Software
Tutorials, best practices, and news for software developers and engineers.

Java in April 2026: Leyden Grows Up, Spring Gets Smarter, and the JVM Quietly Reinvents Itself for the AI Era
- Turker Senturk
- Software
- 15 min read
- 17 Apr, 2026
If you've been half-watching the Java world from the sidelines over the last few years, April 2026 is a good moment to look up. Java 26 shipped in March, the frameworks are catching up fast, and the p
read more
Python 3.4: Beyond Scripting – Building Scalable Systems
- Turker Senturk
- Software
- 13 min read
- 03 Apr, 2026
There's a category of software releases that doesn't make headlines. No flashy syntax changes, no paradigm shifts, no blog posts going viral on Hacker News. Python 3.4 was exactly that kind of release
read more
The Data Lakehouse Explained: Why Apache Iceberg Is Quietly Running the Show
- Turker Senturk
- Software
- 13 min read
- 31 Mar, 2026
Picture this: it's 2015, your company just dumped three years of raw clickstream data into an S3 bucket and called it a "data lake." Fast forward to today, and nobody remembers the schema. The data sc
read more
Java 26 Released: What Shipped in March 2026
- Turker Senturk
- Software
- 8 min read
- 30 Mar, 2026
March 2026 is the biggest month on the Java calendar. Java 26 shipped. JavaOne came back. The ecosystem delivered a stack of framework releases. Here's everything that matters. Java 26: What Dropped o
read more
The LiteLLM Supply Chain Attack: How a Security Scanner Became a Backdoor
- Turker Senturk
- AI , Software
- 7 min read
- 27 Mar, 2026
If you work with AI APIs, there's a reasonable chance LiteLLM is somewhere in your dependency tree — possibly without you ever explicitly installing it. It's one of the most widely used Python librari
read more
Python 3.3: The Version That Quietly Rewired Everything
- Turker Senturk
- Software
- 13 min read
- 26 Mar, 2026
September 2012. The iPhone 5 had just launched. Gangnam Style was breaking the internet. And somewhere in the Python changelog, three features shipped that most developers barely noticed — yet went on
read more
Python 3.2 and concurrent.futures: The Release That Made Python 3 Worth Using
- Turker Senturk
- Software
- 14 min read
- 25 Mar, 2026
Let's be honest about something: Python 3.0 was kind of a disaster. Not a catastrophic, "burn it all down" disaster — more like the kind of disaster where you show up to a party with great intentions,
read more
Cleaning the Slate: The Radical Engineering Behind Python 3.0
- Turker Senturk
- Software
- 8 min read
- 19 Mar, 2026
In the software world, backward compatibility is practically sacred. Libraries, frameworks, entire companies are built on the assumption that updating a language won't torch everything you've already
read more
The Operator That Dethroned a King: Python's Walrus Operator Story
- Turker Senturk
- Software
- 14 min read
- 15 Mar, 2026
On the morning of July 12, 2018, members of the Python community woke up, opened their laptops, and found a message on the python-committers mailing list that would change the trajectory of one of the
read more
AI Coders Can Finally See What They're Building — Antigravity and Uno Platform Make It Happen
- Turker Senturk
- AI , Software
- 12 min read
- 11 Mar, 2026
Here's a scenario every developer knows too well: your AI coding assistant writes a beautiful chunk of code, the compiler gives you a green light, and you feel like a productivity superhero — until yo
read more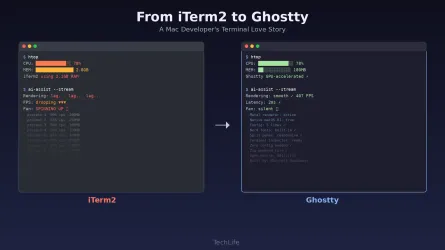
Why I finally traded iTerm2’s features for Ghostty’s GPU renderer
- Turker Senturk
- Software , Technology
- 15 min read
- 09 Mar, 2026
There's a moment every developer remembers. Not the first time they wrote "Hello World" — that's romanticized nonsense. I mean the first time you opened a real terminal, saw a blinking cursor staring
read more
Java roundup featuring Apache Solr 10 release, JDK updates, and Devnexus 2026.
- Türker Şentürk
- Software
- 13 min read
- 09 Mar, 2026
Java Roundup – March 2 2026 A quick pulse‑check If you’ve been living under a rock (or, more plausibly, buried in a monorepo), you might have missed a handful of releases that landed this week. Nothin
read more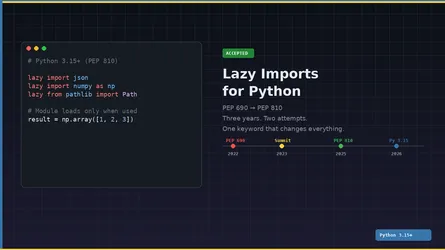
The Story of Python's Lazy Imports: Why It Took Three Years and Two Attempts
- Turker Senturk
- Software
- 14 min read
- 08 Mar, 2026
You run mytool --help and wait. Two seconds. Three. No network requests, no error, no disk thrashing. Just Python dutifully loading PyTorch, NumPy, pandas, and a dozen other heavy libraries it will ne
read more
Vercel Just Proposed a TypeScript-Inspired Upgrade to Python's Type System
- Turker Senturk
- Software , Technology
- 10 min read
- 08 Mar, 2026
If you've ever jumped between a TypeScript codebase and a Python one, you know the feeling. TypeScript gives you this almost magic-like type system where you can slice, dice, and reshape types at comp
read more
Rust 1.94.0 Released with Array Windows and Cargo Improvements
- Türker Şentürk
- Software
- 9 min read
- 08 Mar, 2026
Rust 1.94.0 Is Here – Array Windows, Smarter Cargo Config, and More Stabilized APIs Rust ships a new stable release every six weeks, and 1.94.0 is no exception. It landed on March 5, 2026, and while i
read more
A Senior Engineer's Guide to Prompting AI for Real Code
- Turker Senturk
- Technology , Software
- 13 min read
- 07 Mar, 2026
If your idea of using AI for coding still involves tabbing twice to accept a generic boilerplate function, we need to talk. We're way past the era of mere code completion. As of early 2026, OpenAI Cod
read more
OpenAI Codex and Figma launch a new code-to-design integration.
- Türker Şentürk
- Software
- 13 min read
- 06 Mar, 2026
OpenAI + Figma: When Code Meets Canvas in Real‑Time“The boundary between roles starts to soften because the system helps translate between intent and reality continuously.” – Alexander Embiricos, Code
read more
TypeScript 6 Beta Released: Transitioning to TypeScript 7
- Türker Şentürk
- Software
- 13 min read
- 21 Feb, 2026
TypeScript 6 Beta: The “Cleaning‑Up‑After‑Yourself” Release That Sets the Stage for a Go‑Powered TS 7 When the TypeScript team announced the 6.0 beta a few weeks ago, the headlines were… well, there w
read more
Microsoft releases .NET 11 Preview 1 with Runtime Async and C# 15 features.
- Türker Şentürk
- Software
- 13 min read
- 21 Feb, 2026
.NET 11 Preview 1 — What’s New, What’s Exciting, and What Still Feels Rough Around the Edges When Microsoft announced the first preview of .NET 11 last week, the usual mix of “here we go again” and “l
read more
Eclipse GlassFish 8 is Released
- Türker Şentürk
- Software
- 11 min read
- 17 Feb, 2026
Eclipse GlassFish 8 Is Here – The Enterprise‑Java Platform Gets Its Groove Back Published Feb 17 2026 When I first set up a Java EE server back in 2011, the biggest decision I faced was whether to wr
read more
Apple introduces a new video podcast experience on Apple Podcasts using HLS technology.
- Türker Şentürk
- Software
- 12 min read
- 16 Feb, 2026
Apple’s Video‑Podcast Leap: What It Means for Listeners, Creators, and the Future of Audio‑Video StorytellingWhen I first tuned into Serial back in 2014, I was still figuring out how to keep my earbud
read more
Java News Roundup: GlassFish 8.0, OpenHai 1.0, and More
- Türker Şentürk
- Software
- 15 min read
- 09 Feb, 2026
This Week in Java (Feb 2 – Feb 9, 2026): GA GlassFish, AI‑Ready OpenHai, and Two Fresh Early‑Access JDKs If you’ve been living under a rock (or a particularly stubborn java.lang.Thread that refuses to
read more
Introducing GPT-5.3-Codex: Advancing Agentic Coding
- Türker Şentürk
- Software , AI
- 12 min read
- 05 Feb, 2026
GPT‑5.3‑Codex: The Coding Agent That’s Starting to Feel Like a Real Coworker When I first tried the original Codex a few years ago, it felt a bit like handing a junior intern a half‑finished script an
read more
Maven 4 Is Finally Here: Everything You Need to Know About the Biggest Update in 15 Years
- Turker Senturk
- Software
- 9 min read
- 20 Jan, 2026
If you've been building Java projects for any length of time, Maven has probably been your trusty companion — that reliable friend who shows up every day, does the job, and never asks for anything in
read more
Introducing context-driven development for Gemini CLI
- Türker Şentürk
- Software
- 12 min read
- 14 Jan, 2026
When AI Becomes the Project Manager: A Deep‑Dive into Gemini CLI’s Conductor Extension By Alex Kantakuzenos, senior tech reporter – 15 years of watching code turn into products (and sometimes into nig
read more
The Week AI Went Into Overdrive: Software and AI News Roundup (January 12-13, 2026)
- Turker Senturk
- Software
- 13 min read
- 13 Jan, 2026
If you blinked this week, you probably missed about seventeen major announcements in the tech world. Seriously, January 12-13, 2026, felt like someone accidentally hit the fast-forward button on the e
read more
Database Systems and Comparisons in 2025: The Ultimate Guide to Choosing Your Data Home
- Turker Senturk
- Software
- 16 min read
- 13 Jan, 2026
Remember when picking a database was as simple as choosing between Oracle or MySQL? Yeah, those days are gone. In 2025, the database landscape looks less like a simple menu and more like an all-you-ca
read more
The 2026 Memory Safety Mandate: Why We’re Finally Fixing the Foundation of Code
- Türker Şentürk
- Software
- 6 min read
- 05 Jan, 2026
Imagine for a second that 70% of all car accidents were caused by the exact same mechanical failure—say, a specific bolt that just happened to shake loose on every highway in the world. We wouldn't ju
read more
Java December 2025 Roundup: Vault, Micronaut, Gradle & More
- Turker Senturk
- Software
- 2 min read
- 29 Dec, 2025
What's New This Week The Java world's been busy. JDK 26 and 27 early-access builds are rolling out, frameworks are getting smarter about security, and build tools are finally fixing those little annoy
read more
CI/CD Pipelines Explained: How to Ship Software Fast Without Breaking Everything
- Turker Senturk
- Software
- 18 min read
- 26 Dec, 2025
Modern software teams are expected to ship updates multiple times per day. But speed without stability? That's just chaos with fancier tools. The real challenge is building pipelines that move fast an
read more
Java Ecosystem Surge: JDK 26/27 EA, GlassFish 8.0 M15 & Spring Shell 4.0 RC
- Turker Senturk
- Software
- 4 min read
- 22 Dec, 2025
Key HighlightsThe Big Picture: The Java world received a flurry of releases this week, spanning JDK 26/27 early‑access builds, GlassFish 8.0 M15, Spring Shell 4.0 RC1, and dozens of framework updates.
read more
Debezium 3.4 Final: A Feature-Packed Release for Modern Data Pipelines
- Turker Senturk
- Software
- 7 min read
- 22 Dec, 2025
The Debezium team has wrapped up 2025 with a substantial release: Debezium 3.4.0.Final. This version brings a rich collection of new features, performance improvements, and bug fixes designed to make
read more
Apple's iOS 26.2 Brings New App Marketplace & Payments to Japan
- Turker Senturk
- Software
- 4 min read
- 21 Dec, 2025
Key HighlightsThe Big Picture: Apple’s iOS 26.2 changes let Japanese developers use alternative app marketplaces and offer non‑Apple payment methods while adding new safety layers. Technical Edge: A
read more
Java News Roundup: December 8th, 2025
- Turker Senturk
- Software
- 2 min read
- 15 Dec, 2025
Key HighlightsMajor Release: Spring Tools 5.0 is now available, aligning with the next generation of the Spring ecosystem. Java Updates: JDK 26 and JDK 27 early-access builds have been released, featu
read more
Rust 1.92.0 Released: Empowering Reliable Software Development
- Turker Senturk
- Software
- 3 min read
- 12 Dec, 2025
Key HighlightsStabilization Efforts: The Rust team continues to work on stabilizing the never type, with new deny-by-default lints. Improved Linting: The unused_must_use lint no longer warns about Res
read more
ASP.NET Core 10.0: A Major Update with Extensive Improvements
- Turker Senturk
- Software
- 2 min read
- 11 Dec, 2025
Key HighlightsMajor Update: ASP.NET Core 10.0 brings extensive improvements across the framework. Blazor Enhancements: Updated security samples, client-side fingerprinting, and improved WebAssembly di
read more
Samsung Unveils One UI 8.5 Beta
- Turker Senturk
- Software
- 2 min read
- 09 Dec, 2025
Key HighlightsSimplified content creation with Photo Assist and Generative Edit features Enhanced device connectivity through Audio Broadcast and Storage Share Improved security with Theft Protection
read more
Next.js 16: A New Era for Full-Stack Development
- Turker Senturk
- Software
- 3 min read
- 04 Dec, 2025
Key HighlightsNext.js 16 brings a fundamental shift in caching with Cache Components and explicit opt-in caching Turbopack is now the stable default bundler, offering up to 10x faster Fast Refresh and
read more
Java Roundup: Spring Cloud, Quarkus, and Hibernate ORM Updates
- Turker Senturk
- Software
- 2 min read
- 01 Dec, 2025
Key HighlightsSpring Cloud 2025.1.0 released with bug fixes and updates to sub-projects Quarkus 3.30 delivers new features, including support for Jackson @JsonView annotation Hibernate ORM 7.2.0.CR3 p
read more
Docker Desktop 4.50: Revolutionizing Development Workflows
- Turker Senturk
- Software , Security
- 2 min read
- 29 Nov, 2025
Key HighlightsFaster debugging workflows with Docker Debug now free for all users Enhanced security controls with granular control over container behavior and seamless enterprise policy integrations S
read more
Aspire 13: Unlocking Polyglot Development
- Turker Senturk
- Software
- 2 min read
- 27 Nov, 2025
Key HighlightsAspire 13 introduces comprehensive support for Python and JavaScript as first-class citizens Polyglot development enables seamless integration of .NET, Python, and JavaScript application
read more
Git 3.0 Sets 'Main' as Default Branch
- Turker Senturk
- Software
- 2 min read
- 26 Nov, 2025
Key HighlightsGit 3.0 will use 'main' as the default branch for new repositories This change reflects a broader industry shift towards more inclusive naming conventions The update is expected to arriv
read more
Angular 21 Released with AI-Driven Tooling
- Turker Senturk
- Software
- 2 min read
- 25 Nov, 2025
Key HighlightsAngular 21 introduces AI-driven developer tooling for improved onboarding and documentation discovery Zoneless change detection is now the default, reducing runtime overhead and improvin
read more
Revolutionizing Software Quality with Sauce AI
- Turker Senturk
- Software , AI
- 2 min read
- 25 Nov, 2025
Key HighlightsSauce AI for Insights is a dedicated AI agent that simplifies complex test results It enables teams to make better decisions and deliver software quality intelligence The AI agent is par
read more
Java Roundup: November 17th, 2025
- Turker Senturk
- Software
- 3 min read
- 25 Nov, 2025
Key HighlightsJakarta EE 12 is on track for a summer 2026 release, with Milestone 2 expected on December 9 Liberica JDK updates include patches for four CVEs, addressing security vulnerabilities Open
read more
Spring Framework 7 and Spring Boot 4 Released
- Turker Senturk
- Software
- 3 min read
- 23 Nov, 2025
Key HighlightsSpring Framework 7.0 introduces first-class REST API versioning and built-in resilience features Spring Boot 4.0 migrates to Jackson 3 for JSON processing and modularizes auto-configurat
read more
Breaking Down Silos with Grafana
- Turker Senturk
- Software
- 2 min read
- 23 Nov, 2025
Key HighlightsSimplified data analysis: Easily navigate from charts to logs or traces with a single click Enhanced correlations: Leverage third-party data to uncover new insights Streamlined workflow:
read more
Valkey 9.0 Released with Atomic Slot Migrations
- Turker Senturk
- Software
- 2 min read
- 22 Nov, 2025
Key HighlightsValkey 9.0 introduces atomic slot migrations, improving cluster rebalancing Hash field expiration allows individual fields to expire independently Full support for numbered databases in
read more
Google introduced CodeWiki
- Turker Senturk
- Software
- 1 min read
- 21 Nov, 2025
The entire open-source world is now in your hands! Oh my god — what an exaggerated title, right? Actually, no. It isn’t. This became real thanks to Google. On November 13, 2025, Google unveiled CodeWi
read more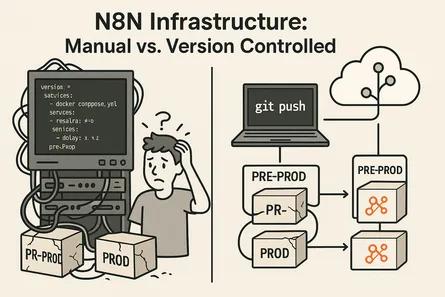
Using Version Control in n8n
- Turker Senturk
- Software
- 2 min read
- 21 Nov, 2025
Using Version Control in n8n We have a server. Or we just got one. Now we want to install n8n on it. We opened the documentation. It says one of the best methods for this is Docker. It even provides a
read more