The Data Lakehouse Explained: Why Apache Iceberg Is Quietly Running the Show
- Turker Senturk
- Software
- 31 Mar, 2026
- 13 min read
Picture this: it’s 2015, your company just dumped three years of raw clickstream data into an S3 bucket and called it a “data lake.” Fast forward to today, and nobody remembers the schema. The data scientist who set it up left. The BI team is still using Excel. Congratulations — you built a data swamp.
If this sounds familiar, you’re not alone. Enterprises spent the better part of a decade oscillating between two bad options: expensive, rigid data warehouses on one end, and chaotic, unmanaged data lakes on the other. The Data Lakehouse is the architectural answer to that pendulum problem — and Apache Iceberg™ is the piece of technology that quietly makes it work.
This is a deep dive into how we got here, what the Lakehouse actually is, and why Iceberg has become the open standard nobody talks about but everyone is now building on top of.
The Two-Tiered Trap: A Problem That Aged Poorly
For decades, the enterprise data world ran on two parallel tracks that barely spoke to each other.
Data Warehouses — think Teradata, then Redshift, then Snowflake — were fast, reliable, and SQL-friendly. Business analysts loved them. CFOs less so: costs ran between $10,000 and $100,000 per terabyte annually. That’s not a typo. Storing a few petabytes in a traditional warehouse was genuinely a budget line item that required executive sign-off.
Data Lakes, sold as the affordable alternative, took a different approach. Dump everything into cheap cloud object storage (S3, ADLS, GCS) at $20–50 per TB per year, and figure out the schema later. This worked great — right up until “later” arrived and nobody could agree on what anything meant or whether the data was trustworthy.
The two worlds created a painful workflow: ETL pipelines shuttling data between the lake and the warehouse, duplicate copies everywhere, and engineering teams spending more time babysitting pipelines than building anything useful.
| Dimension | Data Warehouse | Data Lake |
|---|---|---|
| Data Types | Structured (tabular) | Structured + unstructured |
| Schema | Schema-on-Write (rigid) | Schema-on-Read (flexible) |
| Cost | $10k–$100k/TB/year | $20–$50/TB/year |
| Performance | High (SQL-optimized) | Often poor (metadata overhead) |
| Primary Users | BI analysts | Data scientists, ML engineers |
The core tension? Performance lived in the warehouse. Cost-efficiency and flexibility lived in the lake. Nobody wanted to choose — and the industry eventually decided it didn’t have to.
What Is a Data Lakehouse, Actually?
The term “Lakehouse” gets thrown around a lot, sometimes as genuine architecture and sometimes as marketing fluff. The real thing is specific: it’s an architecture that brings ACID transactions, schema enforcement, and versioning to low-cost, open object storage. You get warehouse-grade reliability without warehouse-grade invoices.
Structurally, a modern Lakehouse has three decoupled layers:
- Storage: Cloud object storage (S3, ADLS, GCS) holding data in open columnar formats like Parquet.
- Metadata: The brains of the operation — tracks transactions, snapshots, and schema changes.
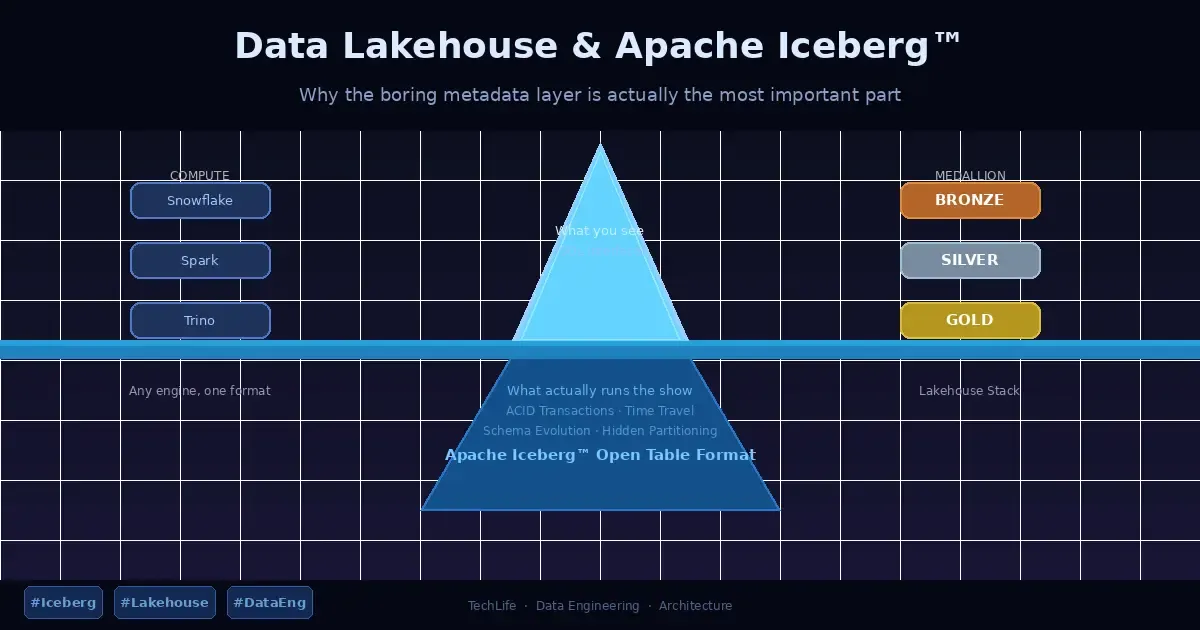
- Compute: Independent, elastic engines (Snowflake, Spark, Trino) that attach and detach on demand.
The key word is decoupled. In a traditional warehouse, storage and compute are bundled together — you pay for both whether you’re running queries or not. Decoupling them means you can scale a massive Spark job for end-of-month reporting without paying for idle storage capacity the rest of the time.
The shift from “Schema-on-Write” rigidity to a governed “Schema-on-Read” model is the architectural pivot. You store raw data with lake-like agility, but you can query it with warehouse-like confidence.
Apache Iceberg™: The Unsung Hero of the Stack
If the Lakehouse is the house, Apache Iceberg is the foundation you never see but absolutely cannot do without.
Iceberg is an open table format — essentially a metadata abstraction layer that sits between your compute engines and your raw Parquet files. Its job is to make a pile of files in S3 behave like a proper database table, complete with transactions, versioning, and schema management. And it does this in a way that no single vendor owns.
That last part matters a lot. Because Iceberg is open and engine-agnostic, your Snowflake, Spark, and Trino clusters can all read from and write to the same tables simultaneously. No proprietary format, no forced migration, no “sorry, you can only access this through our UI.”
Here’s what Iceberg actually gives you in practice:
ACID Transactions — Multiple processes reading and writing at the same time without corrupting each other’s data. This is table stakes for a database; it was conspicuously absent from early Hadoop-based lakes.
Hidden Partitioning — Traditionally, you had to manually manage partition columns and remember to include them in every query or performance fell off a cliff. Iceberg handles partition evolution automatically. You don’t think about the physical layout; Iceberg does it for you.
Schema Evolution — Business requirements change. Tables need new columns, old ones get dropped, fields get renamed. In classic data lakes, this meant rewriting the entire dataset. With Iceberg, schema changes are metadata-only operations — fast, safe, and reversible.
Time Travel — Because Iceberg tracks immutable snapshots of your data, you can query what your table looked like last Tuesday, or roll back an accidental bulk delete. Think of it as Git for your data. You probably won’t use it every day, but you’ll be extremely grateful it exists on the day you need it.
The Snowflake Angle: Open Standards Meet Enterprise Automation
Snowflake’s decision to embrace Apache Iceberg via its Horizon Catalog is worth understanding, because it illustrates the real trade-off architects face.
When you use Snowflake as your Iceberg catalog, you get full SQL read/write support, automated maintenance (compaction, clustering), and table replication — all managed for you. The trade-off is that you’re more tightly coupled to Snowflake’s ecosystem.
When you use an external catalog (say, AWS Glue or a custom REST catalog), you preserve full multi-engine flexibility — Spark can write, Trino can read, Snowflake can also participate. But you’re managing more of the operational complexity yourself.
| Feature | Snowflake as Catalog | External Catalog |
|---|---|---|
| Read/Write | Full SQL support | Read-only via Snowflake; write via REST |
| Maintenance | Automated | You manage it |
| Interoperability | Syncs to Open Catalog | Preserves full ecosystem |
| Table Replication | Supported | Not supported |
The right choice depends on your team. If you have a mature Spark or Trino environment and a strong data engineering team, external catalog gives you maximum flexibility. If you want things to just work without babysitting, Snowflake-managed is easier to operate day-to-day.
The Medallion Framework: Giving Your Data a Quality Ladder
A Lakehouse without structure is just a faster data swamp. The Medallion Architecture is the common pattern for ensuring data moves through a defined quality lifecycle.
Bronze (Raw): The landing zone. Raw ingestion, immutable, exactly as it arrived from the source. This layer exists as a permanent audit trail — if something goes wrong downstream, you can always reprocess from here.
Silver (Cleaned): The enterprise view. Data is deduplicated, validated, and standardized. Records that fail validation don’t get silently dropped — they go to a Quarantine Table, a holding pen where you can inspect and fix bad data without contaminating the main pipeline.
Gold (Curated): Business-ready aggregates and dimensional models, optimized for BI tools. This is what your analysts and dashboards actually consume.
A common mistake is skipping the Silver layer entirely — going straight from Bronze to Gold. The result is duplicated cleaning logic scattered across a dozen reports, each making slightly different assumptions. When the source schema changes, everything breaks at once. The Silver layer isn’t glamorous, but it’s what keeps data scientists and analysts working from the same reality.
The Economics: What “Cheap Storage” Actually Costs
Object storage at $30–50/TB/year sounds like a bargain until you add compute, metadata management, and engineering overhead. The real Total Platform Cost typically lands between $500 and $5,000/TB/year — still far below legacy warehouse pricing, but worth being honest about.
A few levers that actually move the needle:
Decoupled Scaling — Because compute and storage are independent, you don’t pay for 100-node Spark clusters when you’re just storing data. You spin them up when you need them, tear them down when you don’t.
Intelligent Tiering — Historical data that rarely gets queried can move to archive tiers (S3 Glacier and equivalents), reducing storage costs by 40–60%.
Spot Instances — For batch workloads that can tolerate interruption, using spot/preemptible instances can cut compute costs by up to 90%. Not suitable for everything, but effective for nightly transforms.
One hidden cost that often surprises people: egress fees for cross-cloud or cross-region queries. If your data lives in AWS us-east-1 but your Trino cluster is running in GCP, you’re paying data transfer charges every time you query. It’s not catastrophic, but it adds up and is worth accounting for in architectural decisions.
Getting Performance Right: Beyond Just Partitioning
Raw Parquet on S3 won’t give you warehouse-speed queries out of the box. Performance engineering in a Lakehouse requires deliberate layout choices.
Z-Ordering and Liquid Clustering co-locate related records within data files, so a query filtering by customer_id and date doesn’t have to read files scattered across the storage layer. Liquid Clustering is particularly useful for high-cardinality columns where traditional partitioning would create millions of tiny partitions.
The Small File Problem is real and persistent. In cloud object storage, reading a 4KB file has nearly the same overhead as reading a 4MB file — you pay for the round trip, not the data size. Compaction jobs that merge small files into larger ones (target range: 128MB to 1GB) significantly reduce I/O overhead. Automated compaction in managed platforms like Databricks or Snowflake handles this for you; in DIY setups, it’s something you need to schedule explicitly.
Metadata Pruning via min/max statistics allows query engines to skip files that can’t possibly contain relevant data. In well-optimized tables, engines can skip up to 94% of data scans entirely — meaning your query only touches the files it actually needs.
One architectural choice that trips up a lot of engineers: Copy-on-Write (COW) vs. Merge-on-Read (MOR).
- COW rewrites entire data files on every update. Reads are fast because data is always fully merged. Good for read-heavy BI workloads.
- MOR writes small delta files and merges them at read time. Writes are faster and cheaper. Better for streaming ingestion where you’re constantly appending small updates.
There’s no universally correct answer — the right choice depends on whether your bottleneck is read latency or write throughput.
Governance: Security Without Becoming the Data Police
A decentralized Lakehouse still needs centralized governance — otherwise you end up with a compliant-on-paper, chaotic-in-practice mess.
Modern Lakehouse governance covers a few distinct areas:
Access Control — Role-based (RBAC) and attribute-based (ABAC) controls through centralized catalogs like Snowflake Horizon or AWS Glue give you fine-grained security at the row and column level. An analyst can query aggregated sales data without ever seeing individual customer records.
GDPR / Right to Be Forgotten — This is genuinely tricky in immutable storage systems. The Iceberg approach uses Deletion Vectors to logically mask deleted records, followed by Vacuuming and Snapshot Expiration to physically purge data from object storage. Done correctly, it satisfies regulatory requirements without requiring a full table rewrite.
Data Sovereignty — For organizations operating across regions (especially post-Schrems II), using Virtual Private Clouds ensures that sensitive data processing stays within required geographic boundaries.
The broader point: governance done well isn’t about restriction, it’s about enabling safe self-service. When lineage is automated and PII is tagged, analysts can explore data independently without legal having a panic attack.
Build vs. Buy: The Decision That Haunts Every Architecture Review
There’s no universally correct answer here, and anyone who tells you otherwise is probably selling you something.
Integrated Platforms (Snowflake, Databricks): High performance, automated maintenance, and strong tooling ecosystems. You pay a platform premium, and you’re somewhat dependent on their roadmap. For most organizations without a dedicated platform engineering team, this is the pragmatic choice.
Cloud-Native Options (AWS Lake Formation, Google BigLake): Deeply integrated with your existing cloud provider’s services. Works well if you’re committed to a single cloud and want to minimize operational complexity. Less flexible for multi-cloud architectures.
DIY Open-Source (Iceberg + Trino + Spark): Maximum flexibility, lowest direct licensing cost, and full control over your architecture. Also requires a strong engineering team to deploy, maintain, and operate. This path has real advantages for organizations with complex multi-cloud requirements or strict data sovereignty needs — but it’s not a shortcut.
The data sovereignty dimension deserves emphasis: integrated platforms often handle cross-region replication automatically, which is convenient but can create compliance problems if you haven’t thought through where data is physically processed. Open-source or multi-cloud solutions like Starburst let you query data where it lives, avoiding large-scale data migrations.
What’s Next: Apache Iceberg V3 and the Agentic Era
The Lakehouse isn’t standing still. Apache Iceberg V3, currently in public preview, introduces two capabilities worth watching:
Row Lineage — Granular traceability of individual records through the pipeline. Increasingly important as AI model training and debugging requires understanding exactly which data influenced which output.
Variant Data Type — Better native support for semi-structured data (JSON, in particular). As AI workloads generate high-velocity, schema-fluid outputs, having first-class support for variant types in the table format reduces the friction of working with that data at query time.
The broader trajectory is clear: the Lakehouse is evolving from a storage architecture into an operational foundation for both traditional analytics and AI/ML workloads. The same table format that serves a business analyst’s quarterly report also needs to serve an ML pipeline ingesting millions of events per second.
That’s a tall order, and the ecosystem is still maturing. But the direction — open formats, decoupled layers, vendor-agnostic metadata — is the right one.
The Short Version
If you’ve been living with the warehouse-vs-lake trade-off, the Lakehouse architecture is a genuine improvement — not a rebranding exercise. Apache Iceberg provides the open, engine-agnostic table format that makes it practical. The Medallion Framework gives your data a quality lifecycle. And the build-vs-buy decision ultimately comes down to how much operational complexity your team can absorb.
It’s not magic. A poorly governed Lakehouse will still turn into a data swamp. But with the right architecture and discipline, it’s a significantly better foundation than what most enterprises have been working with.
This article is based on publicly available technical documentation and architecture guidance for Apache Iceberg™ and modern data Lakehouse patterns.
Share :
Stay Ahead in Tech
Join thousands of developers and tech enthusiasts. Get our top stories delivered safely to your inbox every week.
No spam. Unsubscribe at any time.








