Snowflake's Arctic Long Sequence Training: How to Train LLMs on 15 Million Tokens Without Selling a Kidney
- Turker Senturk
- AI
- 10 Mar, 2026
- 14 min read
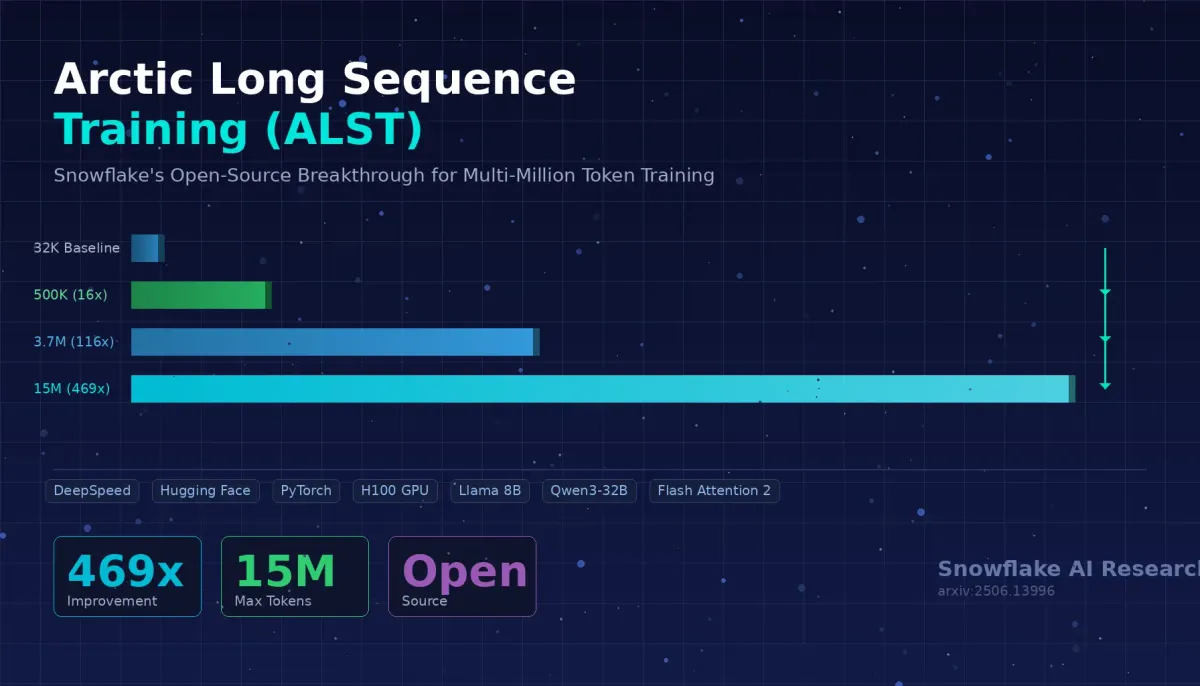
Let’s be honest: training a large language model on long sequences has been the AI equivalent of trying to fit a king-size mattress through a studio apartment door. The mattress is your data, the door is your GPU memory, and you’re standing there sweating, wondering why nobody designed this better. Snowflake AI Research just handed you a bigger door — or, more accurately, a set of clever tricks that make your mattress foldable. Meet Arctic Long Sequence Training (ALST), the open-source framework that takes you from a pathetic 32K token ceiling to a jaw-dropping 15 million tokens on just four nodes of NVIDIA H100 GPUs. That’s a 469x improvement, and yes, it works with your existing Hugging Face models out of the box.
Why Should You Care About Long Sequence Training?
Before we dive into the guts of ALST, let’s talk about why long sequences matter in the first place. If your AI can only “see” 32,000 tokens at a time, that’s roughly the equivalent of reading about 24 pages of a book and then forgetting everything. Try summarizing a 300-page legal contract with that kind of attention span — it’s not going to end well.
Long sequence capability is the unlock for practically every serious AI application you can think of: Retrieval-Augmented Generation (RAG), multi-turn conversations that actually remember what you said three hours ago, long document summarization, and multimodal tasks where images and text need to coexist in the same context window. This is exactly why models like Meta’s Llama 4 Scout now support up to 10 million tokens and Alibaba’s Qwen 2.5 handles 128K. The models can handle long sequences — the problem is that training them at these lengths has been reserved for people with enterprise-grade infrastructure and deep pockets.
ALST changes that equation dramatically.
What Exactly Is the Problem With Training on Long Sequences?
Think of GPU memory like a hotel room. Your model weights, optimizer states, and gradients are the permanent residents — they’ve booked the room and they’re not leaving. For a model like Llama 3.1 8B, those permanent residents alone consume about 144 GiB of memory before you even start training. That’s the model weights (16 GiB for BF16), Adam optimizer states (64 GiB), FP32 weight copies (32 GiB), and gradients (32 GiB). On a single H100 with 80 GiB of memory, you’re already over capacity just from the model itself.
Now here’s the kicker: the activation memory — all those intermediate tensors the model computes during training — grows linearly with sequence length. At 32K tokens, it’s manageable. At 512K tokens, you’re looking at roughly 460 GiB of activation memory for Llama-8B alone. That’s almost six H100s worth of memory just for activations. And we haven’t even talked about CUDA overhead, NCCL communication buffers, and good old memory fragmentation.
In other words, trying to train Llama-8B on anything beyond 32K tokens with a standard Hugging Face setup and DeepSpeed ZeRO Stage 3 will just… crash. Out of memory. Game over.
So How Does ALST Actually Fix This?
ALST isn’t one magic trick — it’s a carefully orchestrated combination of three complementary techniques. Think of it like a three-legged stool: each leg is essential, and together they support something that neither could handle alone.
Leg 1: Sequence Tiling — Slicing the Pizza Instead of Eating It Whole
Here’s a simple analogy. Imagine you need to eat an entire pizza, but your mouth is only so big. The obvious solution? Cut it into slices. That’s exactly what Sequence Tiling does with GPU memory.
Instead of computing logits, loss, and MLP operations across the entire sequence at once (which requires materializing enormous intermediate tensors), Sequence Tiling breaks these computations into smaller chunks along the sequence dimension. Each chunk is processed independently, and only the necessary intermediate values are stored at any given time.
The math is beautiful in its simplicity. For Llama 3.1 8B with a 16K sequence length, a single copy of the logits in FP32 eats about 8 GiB of memory. Since the loss computation touches this twice (forward and backward), you’re looking at 16 GiB just for logits. With Sequence Tiling using 1 GiB shards, that drops to about 2 GiB — a savings of over 14 GiB. The Snowflake team measured a 28% peak memory reduction in practice just from tiling the loss calculation.
But they didn’t stop at logits. They also introduced TiledMLP, which applies the same principle to the MLP layers in each transformer block. Running a single Llama-8B MLP layer on a 256K-length hidden states tensor, tiling achieved roughly 10x memory savings compared to the untiled version. At sequence lengths above 5 million tokens, TiledMLP becomes absolutely critical — without it, the hidden states tensors alone would consume dozens of gigabytes per layer.
The key insight is that operations like linear layers, token embeddings, and per-token loss have no cross-sequence dependencies, so they can be computed tile by tile without affecting correctness. The attention block is the exception — it needs the full sequence — but that’s handled by the next leg of the stool.
Leg 2: Ulysses Sequence Parallelism — Splitting the Work Across GPUs
If Sequence Tiling is about being smarter with one GPU, Ulysses Sequence Parallelism (SP) is about being smarter with many GPUs. Originally developed for Megatron-DeepSpeed, the Snowflake team adapted it to work seamlessly with Hugging Face Transformers — which is where the real accessibility breakthrough happens.
Here’s how it works. The input sequence gets split across participating GPUs. Each GPU processes its shard independently through the non-attention layers (embedding, MLP, etc.). When the attention block is reached — which needs the full sequence — the system performs an all-to-all communication to switch from sequence parallelism to attention head parallelism. Now each GPU has the full sequence but only a subset of attention heads. After attention completes, another all-to-all switches back to sequence parallelism.
The reason this approach is powerful is that Ulysses SP is attention algorithm-agnostic. Unlike Ring Attention (the other popular approach), which requires modifying the attention mechanism itself, Ulysses SP simply recomposes the full sequence and passes it to whatever attention implementation you’re using — FlashAttention2, SDPA, you name it. No model code changes required. That’s a huge deal for the Hugging Face ecosystem where hundreds of model architectures exist.
The Snowflake team also extended the original Ulysses implementation to support modern attention mechanisms beyond just Multi-Head Attention (MHA). It now handles Grouped-Query Attention (GQA) and Multi-Query Attention (MQA) — the attention variants used by virtually every modern LLM including Llama 3.x and Qwen.
Leg 3: PyTorch Memory Optimizations — Sweating the Small Stuff
The third pillar is a collection of PyTorch-level optimizations that individually might seem minor but collectively make a massive difference:
Activation checkpoint offloading to CPU is the big one. Standard activation checkpointing already saves a ton of memory by recomputing intermediate activations during the backward pass instead of storing them. But at long sequence lengths, even the checkpointed hidden states tensors become enormous. At 125K sequence length with Llama-8B, the checkpointed tensors consume about 30.5 GiB across all 32 layers. ALST monkey-patches PyTorch’s checkpoint function to offload these tensors to CPU memory, completely flattening the memory “hill” pattern during training and leaving much more GPU headroom for longer sequences.
PyTorch version management turned out to matter more than expected. The team discovered that a bug in dist.barrier caused over 3 GiB of excess memory usage in PyTorch versions 2.6.0 through 2.7.0. They also found that using all_reduce instead of all_reduce_object saves another 3+ GiB per GPU.
Expandable segments allocator — enabled via a simple environment variable — dramatically improves memory allocation by reducing fragmentation, especially when operating near GPU memory limits.
All of these optimizations stack. And that stacking is what gets you from 32K to 15 million.
What Are the Actual Numbers?
Alright, let’s talk results. Here’s the part where you’ll either get excited or jealous, depending on whether you have access to H100s.
Llama 3.1 8B Results
| Configuration | Max Sequence Length | Improvement Over Baseline |
|---|---|---|
| 1x H100 GPU | 500K tokens | 16x |
| 8x H100 GPUs (1 node) | 3.7M tokens | 116x |
| 16x H100 GPUs (2 nodes) | 7.9M tokens | ~247x |
| 32x H100 GPUs (4 nodes) | 15M tokens | 469x |
Llama 3.1 70B Results
| Configuration | Max Sequence Length |
|---|---|
| 8x H100 GPUs (1 node) | 200K tokens |
| 16x H100 GPUs (2 nodes) | 1.2M tokens |
| 32x H100 GPUs (4 nodes) | 4.0M tokens |
| 64x H100 GPUs (8 nodes) | 10.0M tokens |
Qwen3 32B Results
| Configuration | Max Sequence Length |
|---|---|
| 1x H100 GPU | 230K tokens |
| 8x H100 GPUs (1 node) | 1.55M tokens |
| 16x H100 GPUs (2 nodes) | 4.0M tokens |
| 32x H100 GPUs (4 nodes) | 7.0M tokens |
| 64x H100 GPUs (8 nodes) | 15.0M tokens |
The scaling is roughly linear — double the GPUs, double the sequence length. In fact, it’s slightly superlinear thanks to DeepSpeed ZeRO Stage 3 sharding model parameters across GPUs, which frees up more per-GPU memory as you add nodes.
Feature Ablation: What Actually Matters Most?
The team ran a detailed ablation study on a single 8xH100 node with Llama-8B. Here’s how each feature contributes:
| Features Enabled | Max Sequence Length | Iteration Time |
|---|---|---|
| Baseline only | 32K | 17 seconds |
| + Tiled Logits & Loss (Liger Kernel) | 160K | 2 min 3 sec |
| + Ulysses SP for HF | 1.1M | 9 min 24 sec |
| + Tiled MLP | 1.2M | 11 min 43 sec |
| + Activation Checkpoint Offload to CPU | 2.4M | 43 min 30 sec |
| All features combined | 3.7M | 1 hr 47 min |
The pattern is clear: tiled logits and Ulysses SP get you the initial massive jump, activation checkpoint offloading opens up the real long-sequence territory, and TiledMLP squeezes out the last big chunk — adding 58% more sequence length once all other optimizations are active.
Does Training Quality Suffer?
This is the question everyone asks when they see aggressive memory optimizations: “Sure, it fits, but does it still learn correctly?” The Snowflake team validated ALST against the baseline using Llama-8B at 32K sequence length on a single node. The training loss curves overlap almost exactly — the differences are only visible at the floating-point level. ALST delivers mathematically equivalent training quality to the baseline.
What About the Tricky Details Nobody Mentions?
The 4D Attention Mask Problem
When you’re packing multiple samples into one long sequence (a common efficiency trick), you typically use a 4D causal attention mask to tell the model which tokens should attend to which. But this mask has a shape of [bs, seqlen, seqlen], which means at 125K sequence length, it requires 29 GiB per GPU. At 250K, it balloons to 116 GiB. That’s quadratic growth, and it’s clearly unworkable.
ALST’s solution is elegant: use position_ids instead of explicit attention masks. Position IDs have a shape of [bs, seqlen] — at 125K, that’s just 0.2 MiB. The team had to monkey-patch Hugging Face’s _update_causal_mask to prevent it from creating the mask automatically, but the result is a massive memory saving.
The Loss Sharding Edge Case
When you split a sequence across GPUs for sequence parallelism, cross-entropy loss computation gets tricky. Causal language models shift labels one position to the left for next-token prediction. If you naively shard the sequence and then shift within each shard, you lose tokens at shard boundaries. ALST pre-shifts the labels before sharding, so every token is correctly accounted for across all GPU ranks. This required a small but important change to the Hugging Face Transformers loss API.
CPU Memory Can Be the Bottleneck
Here’s something the headlines don’t tell you: for very large models with activation checkpoint offloading, CPU memory becomes the limiting factor. Llama-70B at 3M sequence length with 32 GPUs needs about 915 GiB of CPU memory per node just for the offloaded activation checkpoints. The team’s nodes had 1.9 TB of CPU RAM and still found that it was the constraining resource, not GPU memory — they literally “left more sequence length on the table” because the GPUs were only about three-quarters full.
How Does ALST Compare to Other Approaches?
| Feature | ALST (Ulysses SP) | Ring Attention | Megatron-LM SP |
|---|---|---|---|
| Attention agnostic | Yes | No (needs custom attention) | No (tied to Tensor Parallelism) |
| HF Transformers compatible | Yes (out of the box) | Requires code changes | Not natively |
| Supports GQA/MQA | Yes | Varies by implementation | Limited |
| Open source | Yes (DeepSpeed + Arctic Training) | Various implementations | Yes |
| Model code changes required | None | Yes | Yes |
| Max demonstrated sequence | 15M tokens | Varies | Varies |
The key differentiator for ALST is the zero model code changes requirement combined with native Hugging Face compatibility. Ring Attention is flexible but requires you to modify the attention mechanism itself. Megatron-LM’s sequence parallelism is tightly coupled to Tensor Parallelism and can’t operate independently. ALST’s Ulysses-based approach sits in the sweet spot of accessibility and power.
What Are the Limitations You Should Know About?
Let’s keep it real — ALST isn’t a magic wand, and the Snowflake team is refreshingly transparent about its constraints:
Sequence parallelism degree is limited by the number of query heads. Llama 3.1 70B has 64 query heads, so SP=64 is your ceiling. You can still scale beyond that by combining SP with data parallelism — running 1,024 GPUs as 16 replicas of SP=64, for instance — but the SP degree itself has an upper bound.
Query heads must be divisible by SP degree. If your model has 9 query heads, your SP options are 1, 3, or 9. No SP=8 for you. The team plans to address this in future work.
Packing short sequences won’t teach long-context understanding. This is crucial and often overlooked. If you concatenate a bunch of 4K samples into one 500K sequence, the model will treat it like a large batch of short samples, not as a single long-context example. You need actual long-sequence training data if you want long-context capabilities.
Performance isn’t the primary focus yet. Since ALST targets post-training (which usually takes just a few days), the team prioritized maximum sequence length over throughput. Iteration times at 15M tokens are about 7.5 hours, which is slow but acceptable for fine-tuning workloads. Future work will address performance optimization.
How Do You Actually Get Started?
ALST is fully open-source and integrated into two projects:
ArcticTraining (the main framework): Head to the Sequence Parallelism project on GitHub for ready-to-use post-training recipes. You can literally drop in your dataset definition and start training.
DeepSpeed: The Ulysses SP for HF and related optimizations are integrated into DeepSpeed >= 0.17.0, making them available to anyone already using the DeepSpeed ecosystem.
The software stack you’ll need is straightforward: PyTorch >= 2.7.1, Flash Attention >= 2.6.4, Transformers >= 4.51.3, and DeepSpeed >= 0.17.0. The team recommends setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True as an environment variable for the best memory allocation behavior.
The Techlife Verdict
Snowflake’s ALST is one of those rare open-source contributions that genuinely democratizes a capability previously locked behind enterprise walls. Training on 15 million tokens isn’t just a flex — it’s the kind of capability that enables entirely new classes of AI applications, from truly understanding long legal documents to maintaining context across extended multi-turn conversations.
The engineering is smart, the approach is practical (no model code changes!), and the fact that it plugs directly into the Hugging Face ecosystem means it’s actually accessible to real researchers and engineers, not just people with custom Megatron-LM setups.
Is it perfect? No. The CPU memory bottleneck for large models is real, the SP degree limitations can be annoying for models with unusual head counts, and the training speed at extreme sequence lengths is still measured in hours per iteration. But for post-training and fine-tuning workloads — which is exactly what most practitioners need — these trade-offs are more than acceptable.
If you’ve ever hit an OOM error while trying to fine-tune a model on long contexts and thought “there has to be a better way,” well… now there is. And it’s free.
Sources:
Share :
Stay Ahead in Tech
Join thousands of developers and tech enthusiasts. Get our top stories delivered safely to your inbox every week.
No spam. Unsubscribe at any time.








