Ai
Explore the cutting-edge world of Artificial Intelligence, Machine Learning, and LLMs. Stay ahead with the latest models and applications.

Gemma 4: Google's Most Capable Open Models Are Here — and They Run on Your Laptop
- Turker Senturk
- AI
- 9 min read
- 03 Apr, 2026
There's a familiar tension in the open-source AI world: the models that are actually capable enough to be useful tend to require hardware that most people don't have, while the models you can run loca
read more
The LiteLLM Supply Chain Attack: How a Security Scanner Became a Backdoor
- Turker Senturk
- AI , Software
- 7 min read
- 27 Mar, 2026
If you work with AI APIs, there's a reasonable chance LiteLLM is somewhere in your dependency tree — possibly without you ever explicitly installing it. It's one of the most widely used Python librari
read more
Harvey Just Hit an $11 Billion Valuation — And It Only Does Legal Work
- Turker Senturk
- AI , Business
- 5 min read
- 27 Mar, 2026
There's a running anxiety in the venture capital world that OpenAI and Anthropic are going to eat everyone's lunch. As the two frontier labs expand into agents, applications, and enterprise deployment
read more
Shield AI Just Raised $2 Billion and Doubled Its Valuation in a Year
- Turker Senturk
- AI , Technology
- 5 min read
- 27 Mar, 2026
When a company's valuation more than doubles in a single year while the product is actively flying combat missions in a war zone, it tends to attract serious institutional money. That's exactly where
read more
Google's TurboQuant Compresses AI Memory by 6x — With Zero Accuracy Loss
- Turker Senturk
- AI , Technology
- 6 min read
- 27 Mar, 2026
Every time you have a long conversation with an AI, your GPU is quietly sweating. It has to keep track of everything you've said — every token, every context — in something called the key-value (KV) c
read more
Anthropic's Most Powerful AI Yet Was Leaked Before It Was Announced
- Turker Senturk
- AI
- 5 min read
- 27 Mar, 2026
Anthropic didn't plan to tell you about Claude Mythos today. A human made a configuration error, and suddenly the world found out anyway. On March 27, 2026, Fortune reported that Anthropic had acciden
read more
Rakuten Reduces Recovery Time by 50% Using Codex
- Türker Şentürk
- AI
- 11 min read
- 11 Mar, 2026
Rakuten’s Secret Sauce: How Codex Turned “Oops” Into “Done” in Half the Time When I first heard that a Japanese e‑commerce giant was letting an AI write code for them, I imagined a scene straight out
read more
Descript uses OpenAI to enable multilingual video dubbing at scale.
- Türker Şentürk
- AI
- 11 min read
- 11 Mar, 2026
How Descript Turned Multilingual Dubbing from a Nightmare into a Scalable Feature When I first tried to dub a short tutorial video from English into German, I ended up with a soundtrack that sounded l
read more
AI Coders Can Finally See What They're Building — Antigravity and Uno Platform Make It Happen
- Turker Senturk
- AI , Software
- 12 min read
- 11 Mar, 2026
Here's a scenario every developer knows too well: your AI coding assistant writes a beautiful chunk of code, the compiler gives you a green light, and you feel like a productivity superhero — until yo
read more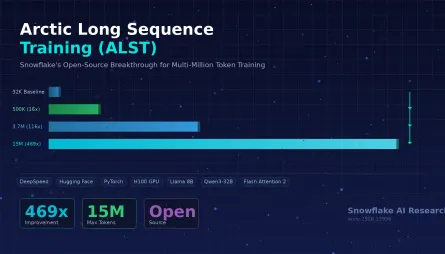
Snowflake's Arctic Long Sequence Training: How to Train LLMs on 15 Million Tokens Without Selling a Kidney
- Turker Senturk
- AI
- 14 min read
- 10 Mar, 2026
Let's be honest: training a large language model on long sequences has been the AI equivalent of trying to fit a king-size mattress through a studio apartment door. The mattress is your data, the door
read more
NVIDIA's 2026 State of AI Report: Adoption, ROI, and Challenges
- Türker Şentürk
- AI
- 11 min read
- 09 Mar, 2026
AI Is No Longer a Fancy Demo – It’s the Engine Driving Real‑World Business Growth When I first walked into a conference hall in 2015 and saw a robot arm “learn” to sort colored blocks, I felt the same
read more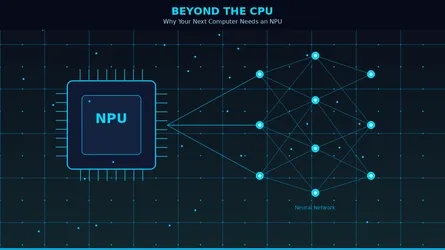
Beyond the CPU: Why Your Next Computer Needs an NPU
- Turker Senturk
- AI , Hardware
- 8 min read
- 07 Mar, 2026
If you've been shopping for a new laptop lately, you've probably noticed a new buzzword popping up everywhere: NPU. It's plastered across spec sheets, product pages, and marketing materials right next
read more
Architectural Elasticity Imperative for Scaling Intelligent Automation
- Türker Şentürk
- AI
- 9 min read
- 07 Mar, 2026
Scaling Intelligent Automation — Why Elastic Architecture Beats “More Bots” When I walked into the Intelligent Automation Conference in London last week, the buzz in the exhibition hall reminded me of
read more
Dyna.Ai Secures Series A Funding to Deploy Agentic AI in Financial Services
- Türker Şentürk
- AI
- 10 min read
- 07 Mar, 2026
Dyna.Ai’s Bet on “Execution‑as‑a‑Service” Could Finally End the AI‑Pilot Fatigue in Finance The pilot problem that’s been haunting banks for years If you’ve ever sat in a boardroom where a slick demo
read more
The Age of the Personal Autonomous Agent: Is OpenClaw Your Next Teammate?
- Turker Senturk
- AI
- 8 min read
- 27 Feb, 2026
Beyond chatbots: How a "lobster-themed" open-source project turned local machines into 24/7 digital assistants. Picture this: It's 10:00 AM on a Tuesday, and you are acting as a human API. You have a
read more
EVMbench: AI agents for smart contract vulnerability detection and patching.
- Türker Şentürk
- AI
- 10 min read
- 23 Feb, 2026
EVMbench: Putting AI Agents on the Smart‑Contract Auditing Hot Seat Why I’m suddenly obsessing over “smart contracts” Look, I’ve been covering everything from the first consumer‑grade VR headset to th
read more
Claude Agent Teams: Moving Beyond Single-Agent AI to Multi-Agent Orchestration
- Turker Senturk
- AI
- 5 min read
- 22 Feb, 2026
Working with AI for software development has traditionally felt like working with a brilliant but siloed junior engineer. You give them a file, they suggest a fix. But when it comes to understanding h
read more
AI attempts to solve First Proof math challenge
- Türker Şentürk
- AI
- 13 min read
- 20 Feb, 2026
OpenAI’s “First Proof” Sprint: How Close Are We to AI‑Generated Mathematics That Holds Up to Peer Review? When I was a kid I used to stare at the back of my high‑school algebra textbook, wondering whe
read more
OpenAI launches 'OpenAI for India' to expand AI access.
- Türker Şentürk
- AI
- 11 min read
- 19 Feb, 2026
OpenAI for India: What the Deal Really Means for the Country’s AI Future When I walked into the India AI Impact Summit in Delhi last week, the first thing I noticed wasn’t the glossy stage or the sea
read more
Gemini can now create music with Lyria 3
- Türker Şentürk
- AI
- 10 min read
- 18 Feb, 2026
A New Way to Express Yourself: How Google’s Gemini App Is Turning Text and Photos into 30‑Second Songs When I first tried to make a mixtape for a friend back in the early 2000s, I spent an afternoon h
read more
Anthropic and Infosys Partner to Develop AI Agents for Regulated Industries
- Türker Şentürk
- AI
- 11 min read
- 17 Feb, 2026
Anthropic × Infosys: Building AI Agents That Can Actually Pass the Regulatory Exam When a Silicon‑valley‑born AI lab teams up with an Indian‑grown consulting giant, the result isn’t just another “AI‑f
read more
NVIDIA Blackwell Ultra Lowers AI Agent Cost
- Türker Şentürk
- AI
- 10 min read
- 16 Feb, 2026
Blackwell Ultra: How NVIDIA’s New Chip Is Making Real‑Time AI Agents Cheaper (and Faster) If you’ve ever tried to run a coding assistant that actually understands a whole codebase, you know the feelin
read more
The Hidden Engineering Behind Fast AI: How LLM Inference Actually Works
- Turker Senturk
- AI
- 12 min read
- 16 Feb, 2026
Here's something that used to keep me up at night: why does ChatGPT feel instant, while my own attempts at running a large language model on a cloud GPU felt like waiting for dial-up internet to load
read more
From Coder to Orchestrator: The Rise of the AI-Powered Developer
- Turker Senturk
- AI
- 25 min read
- 15 Feb, 2026
Remember when being a "10x developer" meant you could type faster, memorize more APIs, and debug obscure errors at 3 AM fueled by nothing but coffee and spite? Those days aren't gone, exactly—but they
read more
Agent Definition Language (ADL): The Missing Standard That Could Finally Tame the Wild West of AI Agents
- Turker Senturk
- AI
- 11 min read
- 09 Feb, 2026
Remember when every website had its own custom markup language before HTML became the standard? Or when APIs were a free-for-all before OpenAPI (Swagger) came along and said, "Hey, maybe we should all
read more
Introducing GPT-5.3-Codex: Advancing Agentic Coding
- Türker Şentürk
- Software , AI
- 12 min read
- 05 Feb, 2026
GPT‑5.3‑Codex: The Coding Agent That’s Starting to Feel Like a Real Coworker When I first tried the original Codex a few years ago, it felt a bit like handing a junior intern a half‑finished script an
read more
Claude Code Subagents: Your Personal Army of Specialized AI Assistants
- Turker Senturk
- AI
- 15 min read
- 23 Jan, 2026
You know that feeling when you're deep in a coding session, and your brain is juggling seventeen different things at once? You're trying to fix a bug, but you also need to review some code, run tests,
read more
OpenAI Finally Crosses the Rubicon: Ads Are Coming to ChatGPT
- Turker Senturk
- AI
- 8 min read
- 23 Jan, 2026
Well, it finally happened. After months of speculation, denials, and what can only be described as corporate tap-dancing around the subject, OpenAI has confirmed what many suspected was inevitable: ad
read more
Cowork: Claude for Enhanced Workflow Automation
- Türker Şentürk
- AI
- 11 min read
- 17 Jan, 2026
When Anthropic first let us play with Claude Code, most of us imagined a “pair‑programmer” that could finish a function or debug a stack trace. That’s exactly what happened—developers fed it snippets,
read more
Building an AI Software Development Team with Claude Code Agents
- Turker Senturk
- AI
- 11 min read
- 17 Jan, 2026
Building an AI software development team with Claude Code agents Claude Code's multi-agent architecture represents a fundamental shift from AI-assisted coding to AI-driven development, where specializ
read more
ChatGPT Go is now available worldwide.
- Türker Şentürk
- AI
- 12 min read
- 16 Jan, 2026
ChatGPT Go Is Finally Everywhere – What It Means for Everyday Users (and the Rest of Us) When OpenAI announced ChatGPT Go back in August 2025, the headline felt almost like a promise whispered in a cr
read more
Veo 3.1 Ingredients to Video: Mobile‑First 4K Creation
- Turker Senturk
- AI
- 2 min read
- 13 Jan, 2026
Key HighlightsThe Big Picture: Veo 3.1 now turns simple image “ingredients” into high‑fidelity, vertical videos that feel alive. Technical Edge: Native 9:16 output and AI‑driven upscaling to 1080p /
read more
Why Traces, Not Code, Are the New Source of Truth for AI Agents
- Turker Senturk
- AI
- 9 min read
- 13 Jan, 2026
If you’ve ever tried to “read the mind” of a GPT‑4‑powered assistant, you know the feeling: you stare at a few lines of orchestration code and wonder why the thing just suggested buying a pineapple pi
read more
When GPUs Meet Molecules: Inside NVIDIA and Lilly’s $1 B AI Lab for Drug Discovery
- Turker Senturk
- AI
- 8 min read
- 13 Jan, 2026
When Jensen Huang took the stage at the J.P. Morgan Healthcare Conference this week, I expected a typical tech‑heavy keynote about GPUs and cloud. Instead, he and Eli Lilly’s chair‑and‑CEO Dave Ricks
read more
Daily AI News Roundup: 09 Jan 2026
- Turker Senturk
- AI
- 8 min read
- 09 Jan, 2026
Nous Research's NousCoder-14B is an open-source coding model landing right in the Claude Code moment Nous Research, backed by crypto‑venture firm Paradigm, unveiled the open‑source coding model NousCo
read more
OpenAI Launches ChatGPT Health: Your AI-Powered Personal Health Assistant
- Turker Senturk
- AI
- 9 min read
- 07 Jan, 2026
OpenAI has officially unveiled ChatGPT Health, a specialized experience within ChatGPT designed specifically for health and wellness conversations. This new feature brings together your personal healt
read more
Weekly AI News Roundup: The 5 Biggest Stories (January 1-7, 2026)
- Turker Senturk
- AI
- 6 min read
- 07 Jan, 2026
Happy New Year, everyone! If you thought 2025 was wild for artificial intelligence, the first week of 2026 just looked at the calendar and said, "Hold my beer." We are only seven days into the year, a
read more
Leona Health Secures $14M to Build the World's First AI Copilot for Doctors on WhatsApp
- Turker Senturk
- AI , Business
- 5 min read
- 06 Jan, 2026
In Latin America, healthcare often begins with a simple WhatsApp message. Patients text their doctors expecting quick responses, much like they would from a food delivery service. But for physicians j
read more
NVIDIA Unveils New Open Models, Data & Tools to Accelerate AI
- Turker Senturk
- AI
- 4 min read
- 06 Jan, 2026
Key HighlightsThe Big Picture: NVIDIA opens a massive ecosystem of models, datasets, and tools that span language, robotics, autonomous vehicles, and healthcare. Technical Edge: Nemotron Speech deli
read more
AMD Just Showed Us What the Future of AI Hardware Looks Like at CES 2026
- Turker Senturk
- AI , Hardware
- 8 min read
- 06 Jan, 2026
Lisa Su doesn't do small announcements. When AMD's CEO took the stage for the CES 2026 opening keynote, she came with a simple message that carried enormous weight: AI should be everywhere, for everyo
read more
NVIDIA Just Spent $20 Billion on a Company You've Never Heard Of—Here's Why That Matters
- Türker Şentürk
- AI
- 6 min read
- 04 Jan, 2026
$20 billion. For a company most people have never heard of. When NVIDIA—the undisputed heavyweight of AI hardware—writes a check that size, you can bet it's not for the office plants. The Groq acquisi
read more
Meta's $2 Billion Manus Bet: Why AI Agents Just Went from Experiment to Infrastructure
- Türker Şentürk
- AI
- 6 min read
- 04 Jan, 2026
147 trillion tokens. 80 million virtual computers. A few months of operation. Those numbers don't just describe a successful startup—they describe infrastructure that's already running at scale while
read more
SoftBank Just Bet $40 Billion on OpenAI—And That's Not Even the Week's Biggest Story
- Türker Şentürk
- AI
- 5 min read
- 04 Jan, 2026
When you casually exit a $5.8 billion Nvidia position to fund your next bet, you're either catastrophically wrong or playing a different game than everyone else. SoftBank chose the latter this week, d
read more
Can We Ever Know If AI Is Conscious? A Cambridge Perspective
- Turker Senturk
- AI
- 5 min read
- 03 Jan, 2026
Here's something that should make you uncomfortable: we're building machines that might be conscious, and we have no way to check. Not "no way right now." Not "no way until better neuroscience tools a
read more
OpenAI Grove Launch: A New Path for Early‑Stage AI Builders
- Turker Senturk
- AI
- 5 min read
- 03 Jan, 2026
OpenAI just posted what might be the strangest job listing in tech: they're looking for 15 people to join their Grove program, and the main qualification is not having your life figured out yet. No st
read more
Gemini 3 Flash Powers Google’s December AI Rollout
- Turker Senturk
- AI
- 3 min read
- 31 Dec, 2025
Google’s December Drop: AI is Finally Getting Boring (In a Good Way) Every December follows the same script. We’re all trying to clear our desks for the holidays, our brains are essentially fried, and
read more
The High-Growth Hybrid: AI Product Manager
- Turker Senturk
- AI
- 4 min read
- 29 Dec, 2025
Ever feel like the tech world throws new job titles at us faster than we can update our LinkedIn? Data Whisperer. Prompt Engineer. Cloud Evangelist. It’s enough to make your head spin. But there’s one
read more
Google’s 2025 AI Research Breakthroughs: Gemini 3, Gemma 3 & More
- Turker Senturk
- AI
- 3 min read
- 24 Dec, 2025
Key HighlightsThe Big Picture: Google’s 2025 AI research pushes models from tools to true utilities, with Gemini 3 leading the charge. Technical Edge: Gemini 3 Flash delivers Pro‑grade reasoning at
read more
AI Skills 2025: LangChain, RAG & MLOps—The Complete Guide
- Turker Senturk
- AI
- 23 min read
- 24 Dec, 2025
If you're building AI systems in 2025, there's a good chance you've already felt the ground shift beneath you. The experimental tools of 2023 have crystallized into production standards. The "nice-to-
read more
AI Transforms Scientific Discovery: How AlphaFold and AI Co-Scientist Are Reshaping Research
- Turker Senturk
- AI
- 14 min read
- 24 Dec, 2025
For decades, scientific productivity has struggled despite increasing funding and larger research teams. Papers became more incremental, experimental projects stretched for years, and the cost of acqu
read more