The Hidden Truth About Vector Databases: What No One Tells You Before You Choose
- Turker Senturk
- AI , Technology
- 10 Nov, 2025
- 6 min read
Vector databases power today’s AI revolution - from ChatGPT’s retrieval capabilities to e-commerce recommendation engines. But choosing the right one is far more complex than comparing benchmark numbers. The landscape is full of marketing claims that obscure critical architectural realities affecting real-world performance.
Why Your “Blazing-Fast” Vector Database Might Actually Be Slowing You Down
Everyone talks about raw search speed, but here’s what vendor benchmarks won’t tell you: the search algorithm itself is rarely your bottleneck.
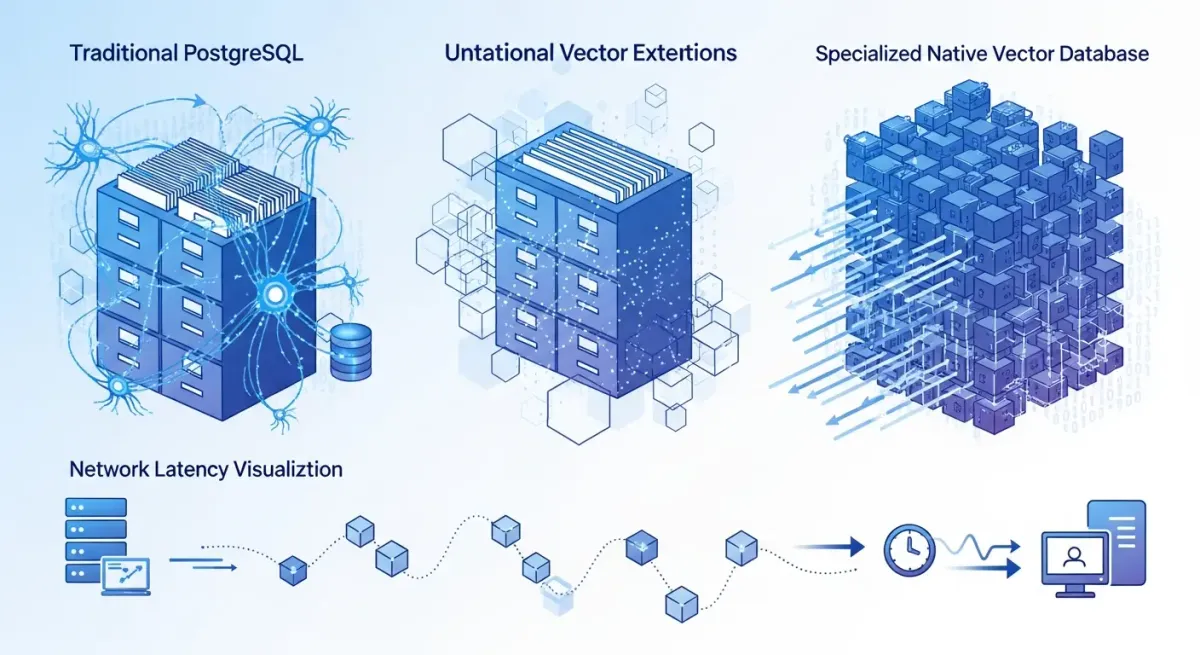
Specialized vector databases like Pinecone promise millisecond search times, and they deliver on that promise. The problem? Network latency from API calls to separate services often dwarfs any search performance gains. When you’re making external API calls to a dedicated vector database, you’re adding 50-100ms of network round-trip time - far more than the few milliseconds saved by a faster algorithm.
The Two-Query Anti-Pattern
Here’s where it gets worse. Many specialized vector services impose restrictive metadata limits. Pinecone limits metadata to 40KB per vector, which sounds generous until you realize it forces a problematic workflow:
- First query: Search the vector database for similar vectors
- Get IDs back (because your actual content exceeded the metadata limit)
- Second query: Fetch the full data from your primary database
This double-hop pattern negates any search speed advantage. You’ve traded a few milliseconds of search performance for hundreds of milliseconds of additional network latency.
PostgreSQL’s Surprising Comeback: The Old Guard Fights Back
The assumption that you need a specialized vector database for serious AI applications? It’s often wrong.
PostgreSQL’s pgvector extension version 0.5.0 introduced HNSW (Hierarchical Navigable Small World) indexing - the same cutting-edge algorithm used by dedicated vector databases. This isn’t legacy technology with vector capabilities bolted on; it’s a fundamental game-changer.
Why HNSW Matters
HNSW is widely recognized as one of the top-performing vector indexing algorithms available. Unlike the older IVFFlat approach, HNSW allows you to create an index on an empty table and add vectors incrementally without impacting recall, and it supports concurrent inserts plus update and delete operations - features that many other HNSW implementations lack.
The Unified Architecture Advantage
By keeping vectors in PostgreSQL alongside your application data, you eliminate:
- Data synchronization issues between separate systems
- Network latency from external API calls
- The two-query anti-pattern (everything lives in one database)
- Additional infrastructure complexity
You gain access to:
- ACID compliance for data consistency
- Powerful JOINs combining vector and relational data
- Mature backup and recovery systems
- Decades of optimization and tooling
The Fundamental Trade-Off: Performance vs Capabilities
The vector database landscape splits into two distinct architectural philosophies:
| Aspect | Native Vector Systems | Extended Relational Systems |
|---|---|---|
| Examples | Qdrant, Milvus, Weaviate | PostgreSQL + pgvector |
| Built For | Vector operations from the ground up | General-purpose database with vector support |
| Performance | Optimized for pure vector workloads | Excellent with room for optimization |
| Implementation | Often Rust/Go for maximum speed | Standard PostgreSQL with extension |
| Feature Set | Vector-focused, narrower scope | Comprehensive database features |
| Data Management | Separate system, sync required | Unified with application data |
| Maturity | Newer, evolving rapidly | Decades of proven reliability |
| Best For | Extreme performance requirements | Most production applications |
When to Choose Native Systems
Native vector databases excel when you need:
- Maximum throughput for pure vector operations
- Specialized features like GPU-accelerated indexing
- Massive scale with billions of vectors
- Sub-millisecond latency as an absolute requirement
When Extended Systems Win
PostgreSQL with pgvector shines for:
- Unified architecture where vectors live with business data
- Complex queries combining vector and relational operations
- Mature ecosystem with existing PostgreSQL expertise
- Simplified deployment without managing separate services
Filtering: The Ultimate Litmus Test
While every vector database claims filtering support, how they implement it determines real-world performance.
Consider this e-commerce query: “Find sweaters visually similar to this image, but only Brand X, under $50, available in blue, and in stock.” This hybrid search - combining semantic similarity with precise filters - reveals architectural strengths and weaknesses.
The Three Filtering Approaches
1. Pre-Filtering (Inefficient) The system calculates which vectors match the filter before searching, but this breaks HNSW graph connections, severely degrading accuracy when filters are selective.
2. Post-Filtering (Wasteful)
The database finds nearest neighbors from the entire dataset, then discards non-matching results. When you apply a filter after vector search, you often end up discarding a large portion of the results that the vector search returned. If only 1% of sweaters match your criteria, the system might retrieve 10,000 results just to return 100 relevant ones.
3. Integrated Filtering (Optimal) Qdrant’s query planner dynamically chooses strategies based on filter selectivity - it can retrieve vectors by filtering conditions and re-score them, or perform search using the vector index while checking filter conditions dynamically during HNSW graph traversal. This approach limits condition checks by orders of magnitude compared to traditional pre-filtering.
Why This Matters
Filtering performance isn’t academic - it’s the difference between a 50ms query and a 5-second timeout. Systems with sophisticated filtering can:
- Handle selective filters efficiently
- Maintain sub-second response times at scale
- Support complex multi-condition queries
- Scale to production workloads
Making the Right Choice for Your Application
The question isn’t “Which vector database is fastest?” but rather “Which architecture best serves my complete requirements?”
Decision Framework
Choose PostgreSQL + pgvector if you:
- Need vectors alongside relational data
- Value architectural simplicity
- Want to leverage existing PostgreSQL expertise
- Require complex JOIN operations
- Have sub-billion vector scales
Choose Native Vector Systems if you:
- Need extreme performance at massive scale
- Can justify separate infrastructure complexity
- Have billions of vectors
- Require sub-10ms query latency
- Need specialized features like GPU acceleration
Consider Hybrid Approaches if you:
- Have distinct hot/cold data patterns
- Need both relational and vector capabilities
- Can manage multiple database systems
- Have clear performance bottlenecks to address
Key Takeaways
- Network latency often exceeds algorithm speed gains - a unified architecture eliminates this bottleneck
- PostgreSQL + pgvector is production-ready with HNSW support matching specialized databases
- Architectural philosophy matters more than raw benchmarks - consider your complete requirements
- Filtering implementation separates the contenders - integrated filtering approaches deliver superior performance
- The “best” database depends on your specific needs - there’s no universal winner
The vector database decision requires careful analysis of your architecture, scale, and requirements. For many applications, PostgreSQL with pgvector offers an optimal balance of performance, simplicity, and capabilities. For others pushing extreme scale or needing specialized features, native vector databases justify their complexity.
Choose based on your actual needs, not marketing benchmarks.
Sources:
Tags :
Share :
Stay Ahead in Tech
Join thousands of developers and tech enthusiasts. Get our top stories delivered safely to your inbox every week.
No spam. Unsubscribe at any time.