5 MLOps Truths That Will Save You Months of Wasted Effort
- Turker Senturk
- AI , Technology
- 10 Nov, 2025
- 7 min read
The MLOps landscape has exploded with hundreds of tools, creating what Gartner calls a “glut of innovation.” This abundance creates a paralyzing problem: making informed choices becomes nearly impossible when tools appear similar on the surface but solve fundamentally different challenges. If you’ve felt overwhelmed trying to compare platforms, you’re experiencing the industry’s most common pitfall.
This guide cuts through the confusion by focusing on the counter-intuitive lessons learned from real-world implementations. Instead of drowning in feature lists, you’ll learn to think about MLOps tools through the lens of the specific problems they actually solve.
Problem #1: Not All “MLOps Platforms” Solve the Same Problem
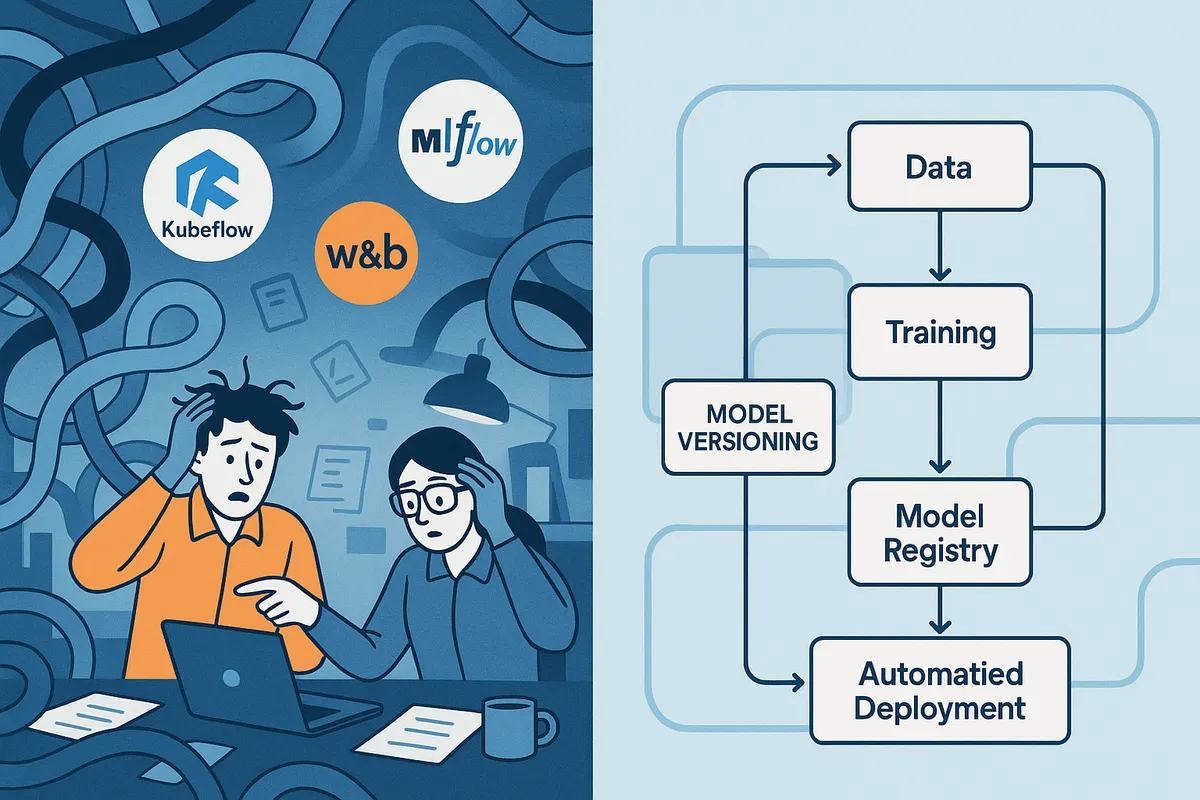
The single most expensive mistake teams make is treating Kubeflow and MLflow as interchangeable options. This isn’t just inaccurate—it reveals a fundamental misunderstanding that leads to months of wasted development time.
Here’s the reality: These tools operate at completely different layers of your ML infrastructure.
Kubeflow is a container orchestration system built on Kubernetes. It’s designed for building and deploying scalable ML workflows at an infrastructure level. Adopting Kubeflow means committing to Kubernetes and typically requires dedicated platform engineers to manage the complexity.
MLflow is a lightweight, application-level tool focused on experiment tracking and model management. Data science teams can adopt it with minimal infrastructure overhead, and it doesn’t dictate how or where your training actually happens.
Think of it this way: if your MLOps workflow were a professional kitchen, Kubeflow is the head chef orchestrating every station, timing, and resource on an industrial scale. MLflow is the meticulous recipe book where every experiment’s ingredients, parameters, and results are documented for perfect reproducibility.
Valohai, an MLOps platform provider, captures this distinction perfectly:
Kubeflow is, at its core, a container orchestration system, and MLflow is a Python program for tracking experiments and versioning models. When you train a model in Kubeflow, everything happens within the system. With MLflow, the actual training happens wherever you choose to run it, and the MLflow service merely listens in on parameters and metrics.
The Right Question to Ask
Instead of “Which platform is best?”, ask yourself: “Which specific problem do I need to solve right now?”
Getting this wrong means you might hire an expensive platform team for a Kubernetes infrastructure you don’t need, or conversely, task data scientists with building production systems using tools never designed for that purpose.
Problem #2: Your Experiment Tracker Won’t Schedule Your Production Jobs
This truth typically surfaces in a moment of panic. Teams successfully adopt MLflow or Weights & Biases for tracking experiments, then suddenly realize: “How do I run my models on a schedule?”
This question exposes a critical architectural misunderstanding. The correct mental model is a clear “lab-to-factory” separation:
The Lab: Experiment Trackers
Tools: MLflow, Weights & Biases
Purpose: Run experiments, validate results, and publish versioned models to a central Model Registry.
The Factory: Orchestrators
Tools: Apache Airflow, Kubeflow Pipelines
Purpose: Retrieve specific model versions from the Registry and execute them on new data according to schedules—handling batch inference, model retraining, and production workflows.
Understanding this separation prevents a catastrophic mistake: building your entire production system around a tool never designed for execution. This realization saves teams from months of emergency re-platforming when their “experiment tracker” inevitably fails to meet production scheduling demands.
Problem #3: The Real Battle—Polished Cloud Service vs. Open-Source Control
Your team is split. Engineers champion MLflow’s flexibility and open-source freedom. Data scientists love Weights & Biases’ polished interface and collaborative features. This isn’t just a feature comparison—it’s a fundamental clash of values.
The most significant difference between W&B and MLflow isn’t in their feature lists, but in their core philosophies:
Weights & Biases is a polished Software-as-a-Service platform prioritizing seamless user experience.
MLflow is a flexible open-source framework prioritizing modularity and complete control.
Think of it like housing options: W&B is a fully-furnished apartment—move in today and be productive immediately, but you can’t knock down walls. MLflow is a plot of land with building permits—total freedom to build exactly what you need, but you must pour the foundation yourself.
Key Trade-offs
| Factor | Weights & Biases (W&B) | MLflow |
|---|---|---|
| Cost Model | Predictable subscription pricing | Free software, but you pay for hosting infrastructure and engineering time |
| Control & Security | Managed security model, data hosted by W&B | Complete data sovereignty, full control over security policies |
| User Experience | Polished collaborative UI, built for visual analysis | Technical flexibility through APIs, deep customization possible |
| Time to Value | Immediate productivity, minimal setup | Requires infrastructure setup and ongoing maintenance |
| Best For | Teams prioritizing speed and collaboration | Teams requiring data control or in regulated industries |
This choice is strategic, not technical. If your most valuable resource is time-to-market, a managed service accelerates your data scientists’ productivity. If it’s control over data and infrastructure, the investment in open-source is essential. Misaligning this decision with your organization’s priorities guarantees friction and wasted resources.
Problem #4: Hyperparameter Tuning Is Science, Not Guesswork
Many teams approach hyperparameter optimization by manually adjusting values or running Grid Search. For non-trivial models, this is like finding a needle in a haystack by examining every single piece of hay—inefficient and expensive.
The Critical Insight
Not all hyperparameters matter equally. Grid Search wastes compute exploring unimportant parameters while barely sampling the few that truly impact performance. Random Search is far more effective because it explores the full range of each parameter independently, dramatically improving your odds of finding optimal values.
Scientific Approaches to HPO
| Method | How It Works | When to Use |
|---|---|---|
| Random Search | Randomly samples parameter combinations | Baseline approach, always better than Grid Search |
| Bayesian Optimization | Uses past results to intelligently focus on promising areas | When you have budget for longer searches and want optimal results |
| HyperBand | Quickly terminates unpromising trials, reallocates budget to better performers | When you need to evaluate many configurations efficiently |
Parameter Priority
According to Andrew Ng’s widely-cited lecture notes, focus your optimization efforts in this order:
- Learning Rate (most important)
- Momentum Beta
- Mini-batch Size
- Number of Hidden Layers
Applying scientific HPO methods directly impacts your bottom line: reduced cloud compute costs, faster time-to-market with better models, and liberation from soul-crushing manual parameter tweaking.
Problem #5: Reproducibility Means Packaging Everything
“It works on my machine” should be unacceptable in any serious ML team. If you think git pull ensures reproducibility, you’re headed for disaster. Production-grade reproducibility requires packaging your entire project—code, dependencies, and configuration—into a standardized, runnable format.
The MLflow Projects Solution
MLflow Projects provides a standard format ensuring code runs reliably anywhere, by anyone. A proper project includes:
- Source code for the project
- Software dependencies specified in environment files (e.g.,
conda.yml) - Configuration and parameters defining execution
- Entry points or commands for running the code
This solves the chronic problem where code working perfectly for one developer mysteriously fails for another. By bundling code with its complete environment, you ensure experiments can be reliably reproduced every time.
This comprehensive packaging approach is the cornerstone of reliable MLOps. It enables seamless handoffs from experimentation to production and creates auditable, trustworthy assets. A model built today can be understood, rerun, and validated months or years later—the absolute foundation for ML systems businesses can depend on.
Rethink Your Approach
Navigating MLOps becomes dramatically easier when you shift perspective. Instead of comparing endless feature lists, focus on understanding the core problems, philosophies, and architectural trade-offs behind each tool.
Before starting your next platform evaluation, ask yourself:
“What is the simplest tool that solves my team’s biggest bottleneck today?”
This single question will save you more time and money than any feature comparison ever could. The “best” MLOps tool doesn’t exist—only the right tool for your specific challenges, team structure, and organizational priorities.
Sources: Based on analysis from Gartner research on MLOps platforms, Valohai technical documentation, Andrew Ng’s machine learning course materials, and MLflow official documentation.
Tags :
Share :
Stay Ahead in Tech
Join thousands of developers and tech enthusiasts. Get our top stories delivered safely to your inbox every week.
No spam. Unsubscribe at any time.