Optimize LLM Costs with ScyllaDB Semantic Caching
- Turker Senturk
- AI
- 27 Nov, 2025
- 2 min read
Key Highlights
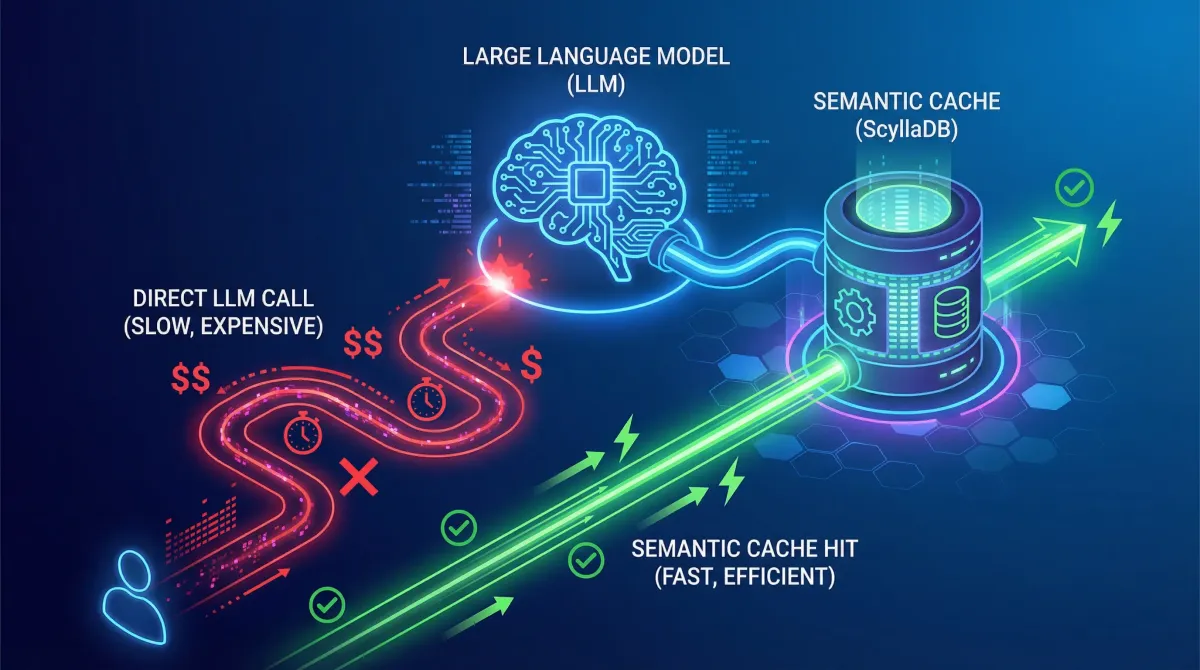
- Semantic caching reduces LLM costs and latency by storing frequent queries and their responses.
- ScyllaDB’s Vector Search enables efficient semantic caching for large-scale LLM applications.
- Combining LLM APIs with ScyllaDB’s low-latency database optimizes performance and cost.
The increasing adoption of Large Language Models (LLMs) in various applications has led to significant concerns about costs and latency. As LLMs continue to grow in complexity and size, the need for efficient and cost-effective solutions becomes more pressing. This move reflects broader industry trends towards optimizing AI workloads and reducing operational overhead. ScyllaDB’s semantic caching offers a promising solution to these challenges, allowing developers to reduce the number of LLM calls and improve response times.
Understanding Semantic Caching
Semantic caching is a technique that stores the meaning of user queries as vector embeddings, enabling fast and efficient retrieval of similar queries. By comparing the vector embeddings of new queries with those stored in the cache, semantic caching can return cached responses instead of calling the LLM. This approach is particularly useful for applications with repeated or semantically similar queries, where identical responses are acceptable. ScyllaDB’s Vector Search feature is essential for building a semantic cache, as it allows for fast and efficient vector searches.
Implementing Semantic Caching with ScyllaDB
To implement semantic caching with ScyllaDB, developers need to create a caching schema, convert user input to vector embeddings, and calculate similarity scores using ScyllaDB’s Vector Search syntax. The key steps involve:
- Creating a keyspace and table to store cached queries and responses
- Converting user input to vector embeddings using a chosen embedding model
- Calculating similarity scores using ScyllaDB’s Vector Search syntax
- Implementing cache logic to decide whether to serve a response from the cache or call the LLM
Conclusion and Next Steps
ScyllaDB’s semantic caching offers a powerful solution for optimizing LLM costs and latency. By reducing the number of LLM calls and improving response times, developers can create more efficient and cost-effective AI applications. To get started with semantic caching, explore ScyllaDB’s Vector Search examples on GitHub and discover how to build low-latency vector search engines for your LLM applications.
Source: Official Link
Tags :
Share :
Stay Ahead in Tech
Join thousands of developers and tech enthusiasts. Get our top stories delivered safely to your inbox every week.
No spam. Unsubscribe at any time.








