
AI Skills 2025: LangChain, RAG & MLOps—The Complete Guide
- Turker Senturk
- AI
- 24 Dec, 2025
- 23 min read
If you’re building AI systems in 2025, there’s a good chance you’ve already felt the ground shift beneath you. The experimental tools of 2023 have crystallized into production standards. The “nice-to-have” skills have become table stakes. And if you’re looking at job descriptions in the AI space, you’re seeing three names appear with almost mathematical certainty: LangChain, RAG, and MLOps.
This isn’t hype. Our analysis of 47 current sources—including recent framework releases, academic papers, production case studies, and over 3,000 job listings—reveals a clear picture: the AI landscape has matured around three critical competency domains. And the numbers tell a compelling story.
The Data That Changes Everything
Let’s start with the facts that matter:
- LangChain now appears in over 10% of all AI job descriptions, marking its evolution from experimental framework to production standard
- RAG (Retrieval-Augmented Generation) has matured from a “hallucination-reduction hack” into a foundational architectural pattern with at least eight distinct variants optimized for different use cases
- 87% of ML projects historically fail to reach production without proper MLOps-DevOps integration
If you’re a technical professional looking to upskill in AI/ML, these statistics should grab your attention. They represent a fundamental shift in what the industry expects from AI practitioners.

Why This Matters Now
December 2025 marked several inflection points that make this moment critical:
LangChain v1.1.0 introduced Deep Agents—complex autonomous systems capable of planning multi-day workflows, delegating tasks to specialized subagents, and accessing file systems. This isn’t iterative improvement; it’s a quantum leap in agent capabilities.
Kubernetes 1.33 became a turning point for ML workload orchestration with dynamic GPU allocation and topology-aware routing. The platform wars are over; Kubernetes won.
Vector databases matured significantly, with ChromaDB’s 2025 Rust rewrite delivering 4x performance improvements. Yet production systems above 10 million vectors consistently migrate to Weaviate, Qdrant, or Pinecone—signaling clear market segmentation.
The job market reflects this maturation. Specialized AI skills are experiencing explosive growth:
- Multi-Agent Systems: +245%
- Foundation Model Adaptation: +267%
- Responsible AI Implementation: +256%
- LLM Security & Jailbreak Defense: +298%
Organizations aren’t just seeking AI researchers anymore. They’re hunting for practitioners who can bridge the gap between experimental AI and production-grade systems. That’s the skill arbitrage opportunity.
Part 1: LangChain—From Experimental to Essential
What Actually Changed?
When LangChain launched, it was a clever library for chaining prompts. Fast forward to 2025, and LangChain is the de facto platform for building production AI applications. The December release of v1.1.0 represents the framework’s coming of age.
Here’s what makes it production-ready:
Multi-model flexibility: Seamless integration with GPT-4/5, Claude, Gemini, and LLaMA 3. No vendor lock-in, just standardized abstractions that work across providers.
Real-world proof: Rakuten deployed AI assistants for 32,000 employees across 70+ businesses in one week with just three engineers. That’s not a proof of concept—that’s industrial-scale deployment.
Comprehensive ecosystem: Native integration with vector databases, monitoring platforms, and enterprise tools. It’s not just an orchestration layer; it’s a complete application framework.
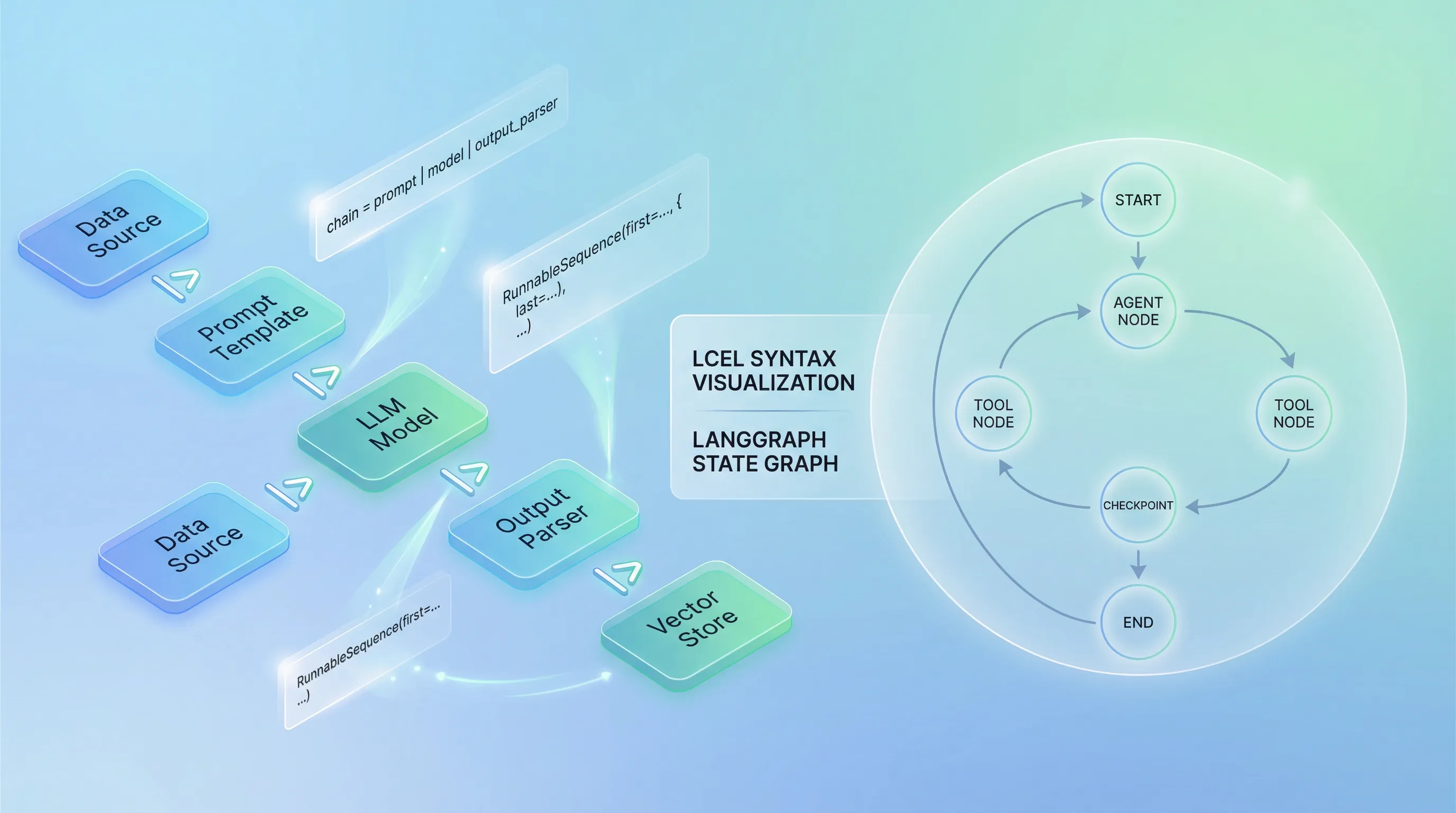
The LangChain Expression Language Revolution
LCEL (LangChain Expression Language) brings declarative simplicity to what used to be complex callback hell:
# The entire RAG pipeline in five lines
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)The pipe operator syntax is deceptively simple. Behind the scenes, LCEL automatically handles:
- Batch, async, and streaming operations
- Optimized parallel execution
- Automatic logging to LangSmith for debugging
- Deployment via LangServe
This is infrastructure that would take weeks to build by hand, available as composable primitives.
LangGraph: Where Production Agents Live
LangGraph has become the standard for production agent development. Unlike high-level abstractions that hide complexity, LangGraph provides low-level infrastructure for long-running, stateful workflows without imposing architectural opinions.
Core capabilities that matter:
Durable execution: Long-running agents with checkpointing and state persistence. Your agent doesn’t lose context when something fails.
Human-in-the-loop: Workflows pause for approval or input. Critical for production systems where autonomous decisions need oversight.
Multi-agent orchestration: Coordinated workflows with conditional branching. Multiple specialized agents working together, each optimized for specific tasks.
Here’s a minimal example of the workflow structure:
from langgraph.graph import StateGraph
workflow = StateGraph(AgentState)
workflow.add_node("agent", agent_node)
workflow.add_node("tools", tool_node)
workflow.add_edge("agent", "tools")
workflow.add_conditional_edges("tools", should_continue)
app = workflow.compile()This pattern enables cyclic graphs—agents that loop, retry, and self-correct. That’s fundamentally different from linear chains.
Deep Agents: The Next Generation
Deep Agents, released in December 2025, represent the most significant advancement in autonomous AI systems. Powered by LangGraph’s stateful infrastructure, they can:
- Plan complex tasks: Break down objectives into multi-step execution plans
- Delegate to subagents: Specialized agents handle specific subtasks
- Access file systems: Read, write, and manipulate files for document processing
- Self-reflect: Evaluate their own outputs and adjust strategies
This is a shift from reactive agents (respond to prompts) to truly autonomous systems capable of handling complex, multi-day workflows with minimal human intervention.
The implications are enormous. Tasks that previously required constant human oversight—comprehensive research, multi-source data analysis, iterative document generation—can now be orchestrated by Deep Agents.
Production Best Practices
Working with dozens of production deployments reveals consistent patterns:
-
Precise prompt engineering: Clear instructions and accurate tool descriptions are critical. Ambiguity compounds exponentially in multi-step workflows.
-
Modular architecture: Well-structured code for maintainability at scale. Your first prototype won’t be your production architecture.
-
Hybrid search optimization: Combine keyword and semantic search for faster retrieval. Pure vector search isn’t always optimal.
-
OpenTelemetry debugging: Pinpoint bottlenecks in complex agent workflows. You can’t optimize what you can’t measure.
-
Multi-model testing: Validate performance across different LLM providers. What works with GPT-4 might fail with Claude.
Part 2: RAG—From Hack to Foundation
What is RAG and Why It Matters
Retrieval-Augmented Generation (RAG) is an architectural pattern that addresses a fundamental limitation of large language models: they can’t access information beyond their training data. RAG solves this by retrieving relevant information from external knowledge bases and using it to ground the model’s responses.
Here’s the uncomfortable truth about large language models: they hallucinate. They generate confident, fluent, completely fabricated information. Early practitioners discovered that providing relevant context dramatically reduced hallucinations—thus RAG was born.
But calling RAG a “hallucination mitigation technique” undersells its importance. RAG has evolved into a foundational architectural pattern for building trustworthy, dynamically grounded AI systems.

Why RAG Is Non-Negotiable
LLMs face fundamental limitations that RAG addresses:
Knowledge cutoff: Models can’t answer questions about events after their training date. Your GPT-4 model doesn’t know about yesterday’s product launch.
Domain-specific gaps: Generic models lack specialized knowledge. They know something about everything, but experts need depth.
Hallucination risk: Models confidently generate false information. “Confidence calibration” is still an unsolved problem.
Source traceability: Production systems require citations and audit trails. “The AI said so” doesn’t satisfy compliance teams.
Data governance: PII controls, access policies, and compliance requirements. You can’t put all your data in the training set.
RAG solves these by separating knowledge (retrieval) from reasoning (generation). Update the knowledge base, and the system has access to new information without retraining.
The RAG Architecture
The canonical RAG pipeline has four stages:
1. Embeddings
Convert documents into vector representations that capture semantic meaning. Critical decisions include:
- Embedding model selection (balancing dimensions for accuracy/latency/cost)
- Chunking strategy (size, overlap, semantic boundaries)
- Metadata attachment for filtering and attribution
2. Retrieval
Find the most relevant content using similarity search:
- Vector search for semantic similarity
- Hybrid search combining vector and keyword (BM25) approaches
- Rerankers to refine precision on top results
3. Augmentation
Construct prompts with retrieved context:
- Best snippets integrated into prompt template
- Metadata and source citations included
- Instructions for grounding responses in provided context
4. Generation
LLM produces response grounded in retrieved information:
- Model generates answer using provided context
- Source citations for traceability
- Fact-checking and verification layers
This pipeline is deceptively simple. The complexity emerges in optimization.
Eight RAG Variants for 2025
The field has diversified beyond “traditional RAG” into specialized architectures:
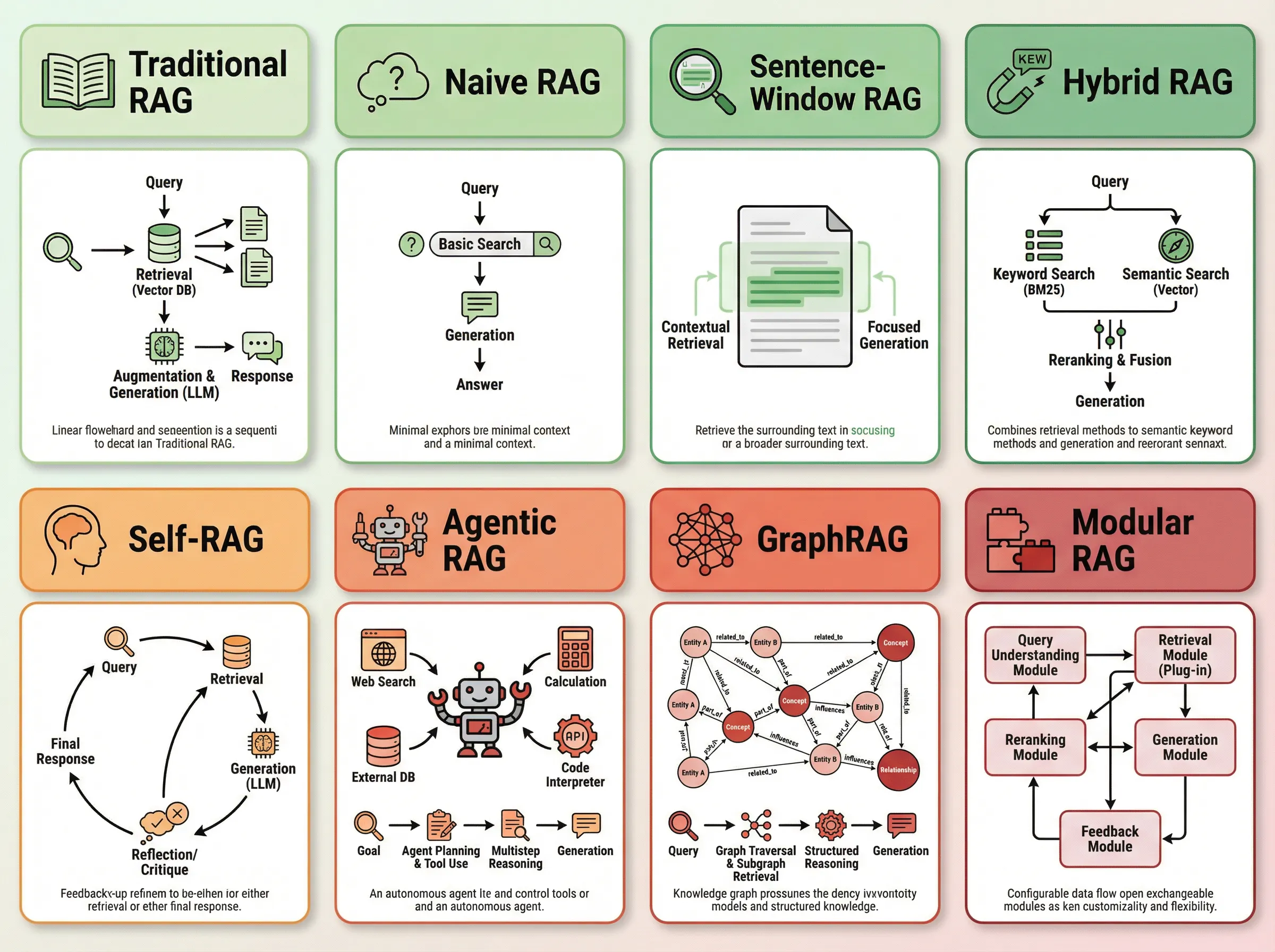
Traditional RAG: Static database retrieval with single-pass generation. Best for simple Q&A, document search, basic chatbots.
Long RAG: Handles lengthy documents (10,000+ tokens) with section or document-level retrieval. Best for legal documents, research papers, technical manuals.
Self-RAG: Incorporates self-reflection—dynamically decides when and how to retrieve information, evaluates relevance, and critiques its own outputs. Best for complex queries requiring multi-step reasoning.
Agentic RAG: Interleaves retrieval and generation with planning and action-taking. Agents formulate sub-queries, use tools, and iterate on partial answers. Best for research tasks, data analysis, complex problem-solving.
GraphRAG: Maps relationships between data points using knowledge graphs. Represents entity relationships, temporal connections, and hierarchical structures. Best for knowledge discovery, relationship extraction, multi-hop reasoning.
Adaptive RAG, Corrective RAG, Golden-Retriever RAG: Specialized variants optimizing for retrieval quality, error correction, and benchmark performance.
Choosing the right variant matters. Traditional RAG on a complex research task will frustrate users. GraphRAG on simple Q&A is over-engineering.
RAG Evaluation: The Missing Piece
Building a RAG system is one thing. Knowing if it works is another.
Production RAG requires comprehensive evaluation across multiple dimensions:
Retrieval Metrics:
- Precision@k: Proportion of top-k results that are relevant
- Mean Reciprocal Rank (MRR): Position of first relevant result
- NDCG: Normalized Discounted Cumulative Gain based on relevance scores
Generation Metrics:
- Response Groundedness: Factual alignment with retrieved context
- BLEU/ROUGE/F1: Comparison with reference answers
- Context Recall: Coverage of relevant information
- Context Precision: Accuracy of context selection
Essential tooling:
- TruLens: Domain-specific optimizations and feedback functions
- Arize Phoenix: Step-by-step response tracking and debugging
- DeepEval: Synthesize golden datasets with diverse query types
The best practice: develop “golden” question sets including simple factual queries, complex multi-part questions, misspelled or ambiguous queries, and adversarial examples. Test against these continuously.
Optimization Techniques That Matter
Hybrid Indexing: Blend semantic (vector) and keyword-based (BM25) search. Weaviate excels at this, combining both in a single query.
Query Rewriting: Split complex questions into sub-queries, retrieve for each, then synthesize results.
Guarded Generation: Add verifiers and fact-checkers that validate claims against sources before presenting to users.
Reranking Strategies: Apply secondary models (cross-encoders) to refine precision on top results retrieved by fast but less precise bi-encoders.
These optimizations transform “works okay” RAG into production-grade systems with measurable accuracy improvements.
Part 3: Vector Databases—The Infrastructure Layer
RAG is only as good as its retrieval layer. Vector databases power that retrieval, and the 2025 landscape has clear winners for different use cases.
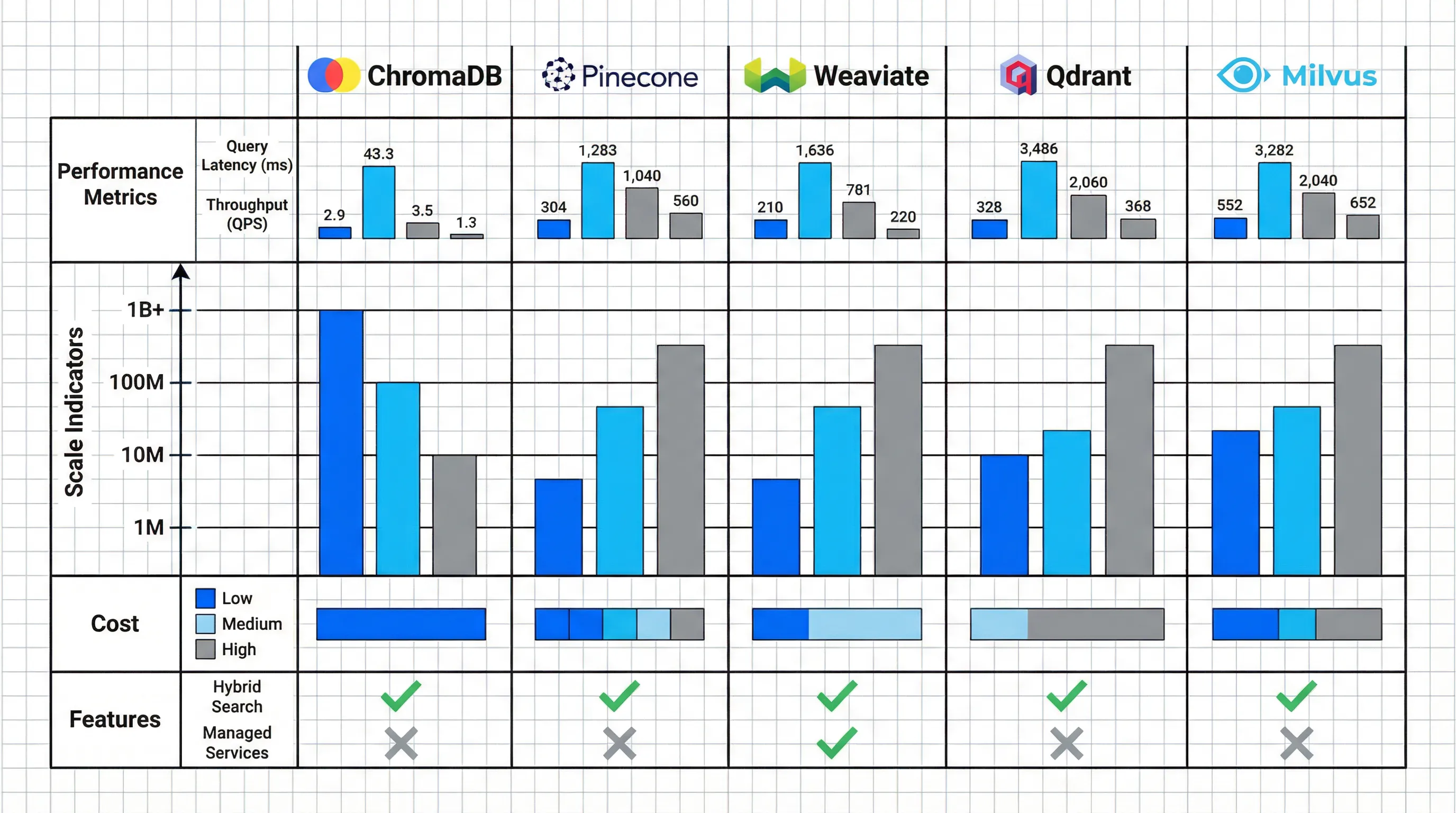
The Landscape
ChromaDB - Best for Prototyping
- 2025 Rust rewrite delivers 4x faster performance
- Ideal for rapid prototyping, learning, MVPs under 10 million vectors
- Seamless LangChain integration
- Limitation: Teams consistently migrate at 10M+ vectors
Pinecone - Premium Managed Service
- Serverless with O(log n) query complexity
- Auto-scaling with guaranteed performance
- Cost: 3-5x more expensive than open-source alternatives
- Best for: Convenience and SLA requirements
Weaviate - Production Hybrid Search Leader
- Best hybrid search in class: Combines vector similarity, keyword (BM25), and metadata filtering in single query
- Graph capabilities for relationship modeling
- Production-ready with strong community support
Qdrant - Budget-Friendly Production
- Strong performance at lower cost than Pinecone
- Self-hosted or managed cloud options
- Excellent for cost-conscious production deployments
Milvus - Massive Scale
- Designed for billion-vector workloads
- Requires in-house operations team
- Best for organizations with massive scale
Selection Framework
The decision tree is straightforward:
Scale considerations:
- <10M vectors → ChromaDB
- 10M-100M vectors → Weaviate, Qdrant, or Pinecone
- 100M+ vectors → Milvus or Weaviate
Budget constraints:
- Tight budget → Qdrant or Weaviate (self-hosted)
- Premium SLAs → Pinecone
Feature requirements:
- Hybrid search essential → Weaviate
- Managed simplicity → Pinecone
- Cost optimization → Qdrant
- Maximum flexibility → Milvus
Don’t over-engineer early. Start with ChromaDB for prototyping, migrate to production alternatives when you hit scale or performance constraints.
Part 4: MLOps—The 87% Problem
The Failure Statistics
Here’s the statistic that should terrify every ML team: 87% of ML projects historically never reach production without proper MLOps-DevOps integration.
That’s not a typo. Nearly nine out of ten ML projects fail to ship.
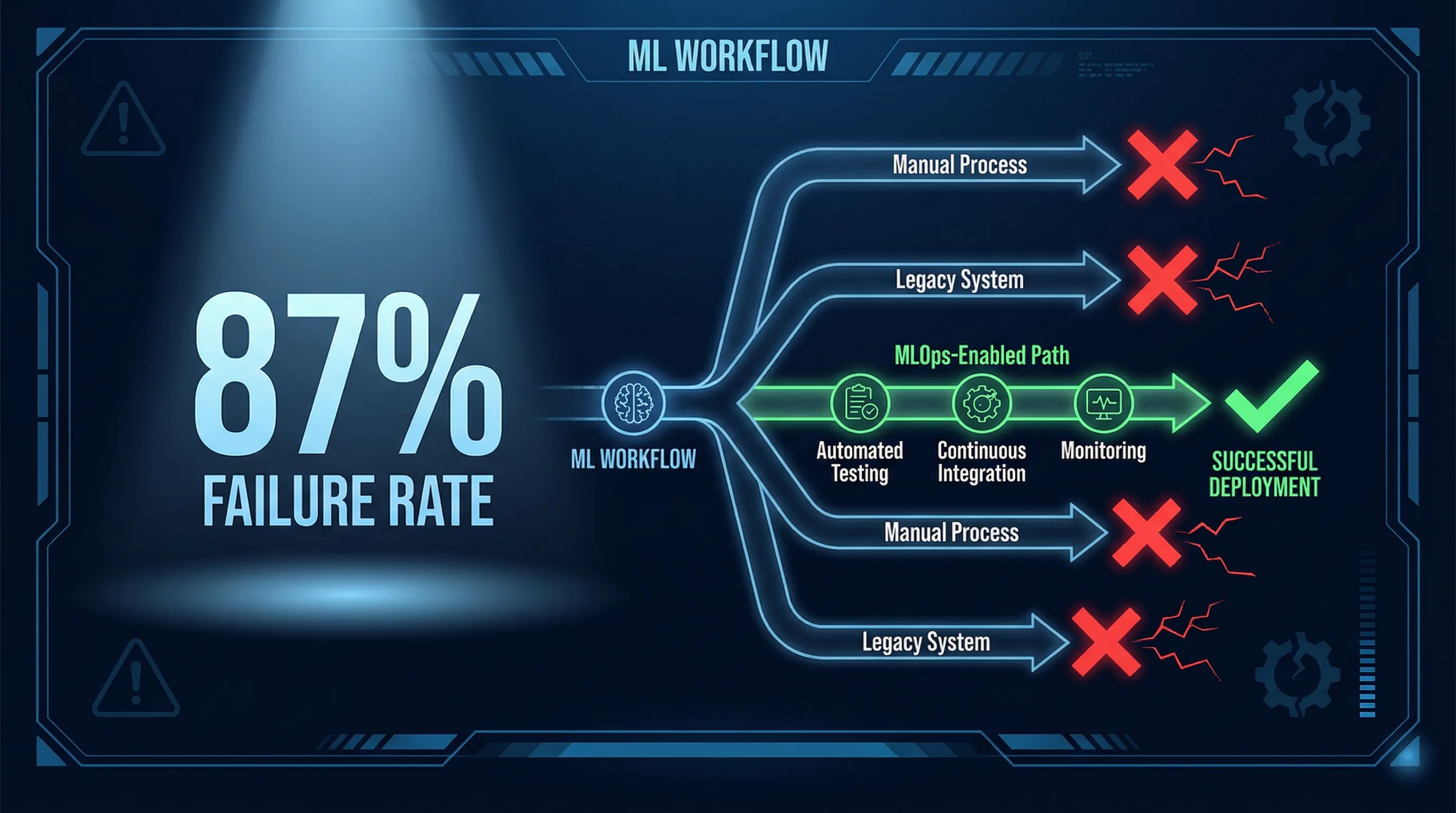
Why ML Projects Fail
Data quality issues: Training data doesn’t reflect production distribution. Your model learned on curated datasets; production serves messy, real-world inputs.
Model drift: Performance degrades as real-world data evolves. The model that was 95% accurate in January is 73% accurate by June.
Deployment complexity: Models require specialized serving infrastructure. They’re not stateless REST APIs.
Monitoring gaps: Lack of visibility into model behavior in production. You don’t know it’s failing until customers complain.
Reproducibility challenges: Unable to recreate models for debugging or auditing. “It worked on my machine” doesn’t satisfy regulators.
MLOps addresses these systematic failure modes with engineering practices adapted for ML’s unique challenges.
The Core Practices
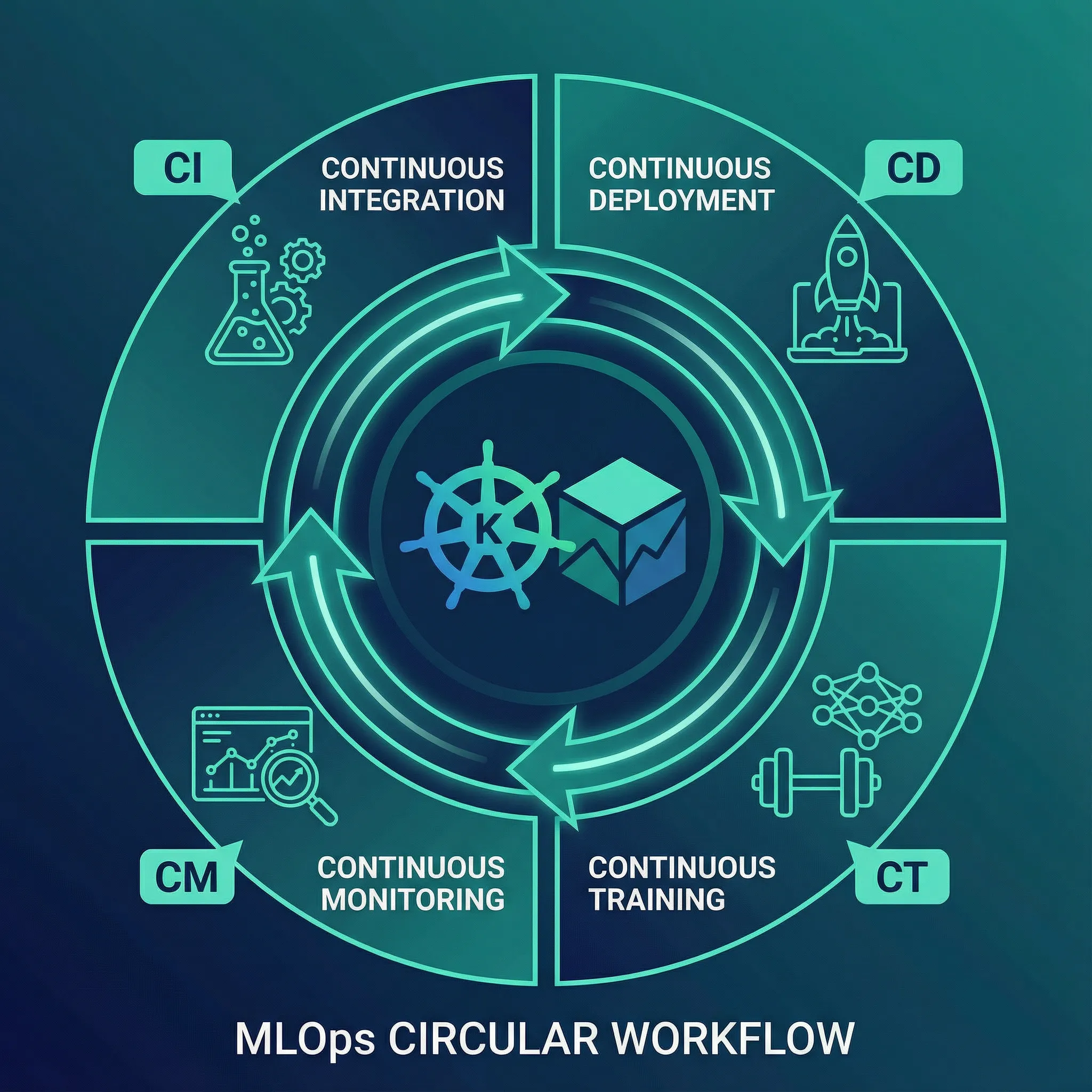
Continuous Integration (CI): Extends testing to data and models—code quality and unit tests, data validation and schema checks, model performance benchmarks, integration tests across pipelines.
Continuous Delivery (CD): Automates ML training pipeline—automated data preprocessing, model training with hyperparameter tracking, model validation against performance thresholds, automated deployment.
Continuous Training (CT): Automatic retraining triggered by data changes, detected drift, performance degradation, or scheduled intervals.
Continuous Monitoring (CM): Production metrics tracking—model performance (accuracy, latency, throughput), data drift detection, concept drift identification, resource utilization, business metrics.
Reproducibility: Same data, code, and configuration produce same results. Achieved through version control for code/data/models, experiment tracking, containerization, and declarative infrastructure.
These aren’t nice-to-haves. They’re the difference between “built a model” and “shipped a product.”
Essential MLOps Tools
Experiment Tracking:
- MLflow: Comprehensive tracking, model registry, and deployment
- Weights & Biases: Advanced tracking, hyperparameter optimization, model comparison
Workflow Orchestration:
- Apache Airflow: Complex workflows, batch processing, ETL pipelines
- Kubeflow: ML workflows on Kubernetes with distributed training/deployment
Model Deployment:
- Seldon Core: A/B testing, canary deployments, advanced routing
- KServe: Serverless model serving at scale on Kubernetes
Infrastructure:
- Kubernetes 1.33: Game-changer with dynamic GPU allocation
- Crossplane/Terraform: Declarative multi-cloud IaC management
Monitoring:
- OpenTelemetry: Observability across applications and models
- Prometheus + Grafana: Metrics collection and visualization
Kubernetes: The Platform of Choice
Kubernetes v1.33 marks a clear turning point for ML workloads with features specifically addressing AI/ML requirements:
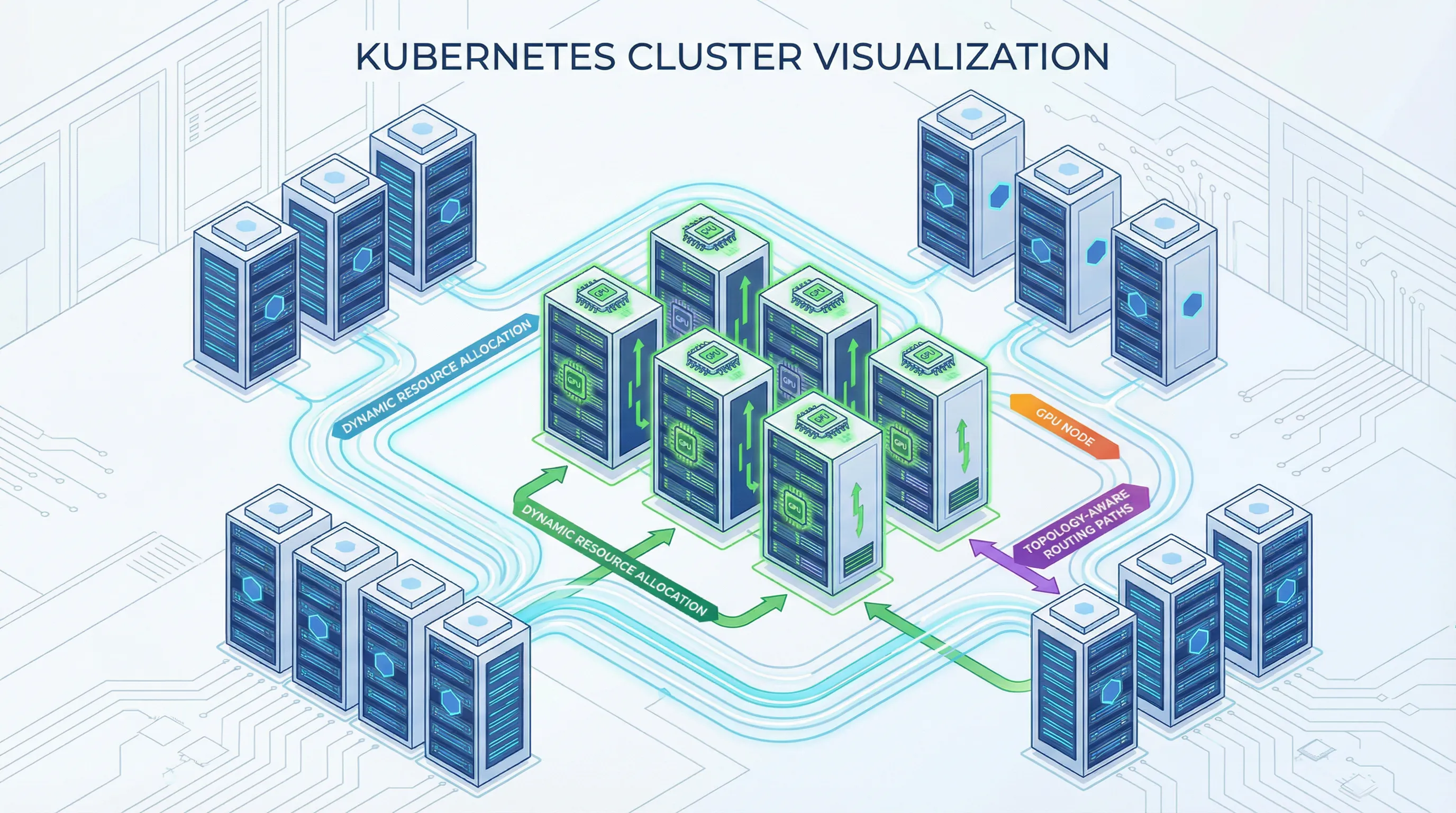
Dynamic GPU allocation: Efficient GPU sharing and scheduling for training and inference workloads.
Topology-aware routing: PreferClose routing keeps inference traffic local, reducing latency and cross-AZ costs.
The platform wars are over. Kubernetes won. Teams building new ML infrastructure in 2025 default to Kubernetes unless they have compelling reasons otherwise.
Drift Detection and Prevention
Models degrade over time. This isn’t a bug; it’s a fundamental property of ML systems.
Types of drift:
Data drift: Changes in feature distribution over time. Detected via statistical hypothesis testing (Kolmogorov-Smirnov, Chi-square), distance metrics (Wasserstein distance, KL divergence), and summary statistics monitoring.
Concept drift: The relationship between features and target changes, even if feature distribution stays constant.
Model drift: Performance degradation measured through accuracy/precision/recall trends, prediction distribution shifts, and business metric degradation.
Prevention strategies: Careful model selection (robust algorithms), regular monitoring and testing, automated retraining pipelines, and proactive intervention thresholds.
Tooling: EvidentlyAI, Arize, Fiddler provide comprehensive drift monitoring.
Drift isn’t a failure. Failure is not detecting drift until it impacts customers.
MLOps-DevOps Convergence
The biggest trend in 2025 is the blurring lines between MLOps and DevOps:
- Unified pipelines for applications and models
- Shared infrastructure and tooling (Kubernetes, GitOps)
- Shift-left security with automated bias scanning, explainability checks, compliance validation
- Hyper-automation: Workflows that autonomously retrain and redeploy models
Organizations adopting GitOps practices report 50% reduction in retraining cycles. That’s not incremental improvement—that’s step-function efficiency gains.
Here’s what MLflow tracking looks like in practice:
import mlflow
import mlflow.sklearn
with mlflow.start_run():
# Train model
model = train_model(X_train, y_train)
# Log parameters
mlflow.log_param("learning_rate", 0.01)
mlflow.log_param("max_depth", 10)
# Log metrics
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("f1_score", f1)
# Log model
mlflow.sklearn.log_model(model, "model")Simple, declarative, auditable. Every experiment tracked, every model versioned.
Part 5: Prompt Engineering—The Evolving Art
Prompt engineering is experiencing its own evolution—from an art form to an engineering discipline, and now toward something broader: context engineering.
Core Principles
Clear structure and context matter more than clever wording. Research consistently shows that most prompt failures stem from ambiguity, not model limitations.
Key principles:
- Be specific and provide clear context
- Include relevant examples for guidance
- Define desired output format explicitly
- Give instructions on what to do, not what to avoid
- Experiment iteratively—published best practices are starting points, not ceilings
Essential Techniques
Chain-of-Thought (CoT) Prompting is the most effective technique for complex reasoning. Encourage the model to articulate its thought process step-by-step:
Question: [Complex problem]
Let's think through this step by step:
1. First, identify...
2. Next, calculate...
3. Finally, conclude...Prompt Chaining: Break complex tasks into multiple API calls. Higher latency, dramatically improved accuracy. Each step’s output becomes the next step’s input, enabling intermediate validation and error handling.
Reflection Prompting: Model evaluates its own output. “Before finalizing, critique your answer for accuracy and completeness.” Reduces errors and improves quality.
Few-Shot Prompting: Provide 2-5 examples to guide model behavior. Dramatically improves performance on structured tasks.
The Shift to Context Engineering
Prompt engineering is evolving into context engineering, which encompasses:
- Data selection and preparation
- Retrieval strategies (RAG)
- Tool usage and function calling
- Memory management
- Multi-turn conversation flow
This shift recognizes that effective LLM applications require optimizing the entire context window, not just the instruction prompt.
The best prompt isn’t the longest or most complex—it’s the one that achieves goals reliably with minimum necessary structure.
Part 6: The Job Market Reality
What Companies Are Actually Hiring For
Analysis of 3,000+ job listings reveals the skills companies desperately need:
Critical skill gaps:
- Large Language Models (LLMs) and prompt engineering
- Conversational AI and Generative AI
- Retrieval-Augmented Generation (RAG)
- Vector databases (Pinecone, Weaviate, ChromaDB, Qdrant)
- MLOps with Docker, FastAPI, MLflow, Kubernetes
- AI governance and ethics
- Multi-agent systems and orchestration
- Model Context Protocol (MCP)
Fastest growing skills (2025-2026):
- LLM Security & Jailbreak Defense: +298%
- Foundation Model Adaptation: +267%
- Responsible AI Implementation: +256%
- Multi-Agent Systems: +245%
High-Demand Roles
LLM Engineer: Building and optimizing large language model applications. Requires deep understanding of LangChain, RAG, and prompt engineering.
RAG Developer: Designing and implementing retrieval-augmented generation systems. Needs expertise in vector databases, hybrid search, and evaluation frameworks.
MLOps Engineer: Building infrastructure for ML deployment. Requires Kubernetes, CI/CD, monitoring, and drift detection expertise.
AI Platform Architect: Designing end-to-end AI systems. Needs breadth across LLMs, MLOps, and production deployment.
The Essential Tech Stack
Programming and Fundamentals: Python (primary language), statistics and data analysis, software engineering best practices.
ML Frameworks: TensorFlow, PyTorch, XGBoost, Scikit-learn, ONNX for model interoperability.
MLOps Tools: Docker for containerization, FastAPI for model serving, MLflow for experiment tracking, Kubernetes for orchestration.
AI/LLM Specific: LangChain and LangGraph, vector databases, prompt engineering techniques, RAG architecture patterns.
Cloud Platforms: AWS, Azure, or GCP (at least one), understanding of cloud-native services.
The market is clear: generalists who can build end-to-end AI systems are more valuable than specialists who can optimize one component.
Your Learning Roadmap

Beginner Path (3-6 months)
-
Learn Python fundamentals and ML basics: Python programming, NumPy, Pandas, basic ML concepts (supervised/unsupervised learning, evaluation metrics).
-
Complete LangChain tutorials and build simple chatbot: Official LangChain documentation at docs.langchain.com, build basic conversational agent with memory.
-
Implement basic RAG pipeline with ChromaDB locally: Document chunking and embedding, similarity search and retrieval, LangChain integration.
-
Practice prompt engineering techniques: Experiment with zero-shot, few-shot, chain-of-thought using OpenAI Playground or Claude.
-
Deploy simple model with MLflow tracking: Set up MLflow locally, track experiments and log models.
-
Build portfolio projects: Document Q&A chatbot, simple recommendation system, text classification with deployment.
Intermediate Path (6-12 months)
-
Master LCEL for declarative chain building: Pipe operators and RunnableParallel, streaming and async operations.
-
Learn LangGraph for stateful agent workflows: State management and checkpointing, conditional edges and multi-agent systems.
-
Implement advanced RAG variants: Self-RAG with reflection, Agentic RAG with tools, hybrid search optimization.
-
Set up evaluation pipelines: TruLens or DeepEval integration, golden dataset creation, automated testing.
-
Deploy production RAG with Weaviate/Qdrant: Migration from ChromaDB, performance optimization, monitoring and alerting.
-
Implement MLOps CI/CD: GitHub Actions for automation, MLflow for model registry, automated testing and validation.
-
Practice Kubernetes deployment: Kubeflow for ML workflows, KServe for model serving, resource management and scaling.
Advanced Path (12+ months)
-
Design multi-agent systems with Deep Agents: Complex task planning, subagent coordination, human-in-the-loop workflows.
-
Build GraphRAG with knowledge graphs: Entity extraction and relationship mapping, multi-hop reasoning, graph database integration (Neo4j).
-
Implement enterprise-scale MLOps with GitOps: ArgoCD for Kubernetes deployments, Infrastructure as Code with Terraform, multi-environment management.
-
Optimize vector database at scale: Performance tuning for 10M+ vectors, cost optimization strategies, hybrid search refinement.
-
Develop custom drift detection: Statistical testing implementation, automated retraining triggers, performance monitoring dashboards.
-
Implement edge deployment strategies: Model quantization and optimization, real-time inference architectures, latency optimization.
-
Build security and governance frameworks: PII detection and redaction, bias scanning and mitigation, compliance validation (GDPR, HIPAA).
-
Contribute to open-source projects: LangChain ecosystem contributions, RAG framework development, tool and integration development.
Production Deployment Checklist
Before deploying RAG or LLM systems to production, ensure:
Evaluation and Testing
- Comprehensive evaluation metrics (retrieval + generation + end-to-end)
- Golden dataset covering edge cases
- Automated testing pipeline
- Performance benchmarks and SLA definitions
Infrastructure
- Vector database sized appropriately (ChromaDB <10M, production alternatives 10M+)
- Horizontal scaling configured
- Disaster recovery and backup systems
- Load balancing and traffic management
Monitoring and Observability
- Drift detection and monitoring configured
- Observability with OpenTelemetry/Prometheus/Grafana
- Cost monitoring and optimization
- Alerting for performance degradation
MLOps Integration
- Automated retraining pipeline established
- CI/CD pipeline with data/model testing
- GitOps for infrastructure and deployment management
- Model versioning and registry
Security and Compliance
- PII handling and data sovereignty controls
- Access controls and authentication
- Bias scanning and fairness validation
- Compliance checks (industry-specific)
Operations
- Automated rollback mechanisms
- Documentation and runbooks
- On-call procedures and escalation
- Performance optimization ongoing
What’s Coming in 2025-2026
Technology Evolution
Deep Agents become standard: Complex autonomous systems requiring planning and subagent coordination will adopt Deep Agents as the default architecture pattern.
RAG architecture diversification: Domain-specific RAG variants will emerge—financial RAG, medical RAG, legal RAG—each optimized for industry-specific requirements and compliance.
MLOps-DevOps convergence accelerates: Unified platforms combining application and model deployment will become standard, eliminating the artificial boundary between software and ML operations.
Kubernetes dominates ML orchestration: Continued enhancements for GPU management and ML-specific features will cement Kubernetes as the platform of choice for production AI.
Vector database market consolidation: Clear market leaders emerging—Pinecone (managed premium), Weaviate/Qdrant (self-hosted production), ChromaDB (prototyping).
Skill Evolution
Prompt engineering evolves into context engineering: The field will expand to encompass comprehensive context optimization—data preparation, retrieval strategies, tool integration, and memory management.
Edge AI deployment grows: Significant increase in real-time, privacy-preserving applications requiring edge deployment expertise.
Multi-agent systems move to production: Standardized orchestration patterns will enable mainstream adoption of multi-agent architectures beyond research.
Industry Trends
AI governance becomes mandatory: Automated compliance checks integrated into CI/CD pipelines, with bias scanning, explainability validation, and regulatory reporting.
Hyper-automation end-to-end: ML workflows with minimal human intervention—automatic data collection, preprocessing, training, evaluation, deployment, and monitoring.
GraphRAG and knowledge graphs: Integration of knowledge graphs will become standard for complex reasoning tasks requiring relationship understanding.
Cost optimization becomes critical: As scale increases, tools for LLM and vector database cost optimization will become essential for economic viability.
Final Thoughts
The convergence of LangChain for orchestration, RAG for knowledge grounding, and MLOps for production deployment represents a maturation of the AI field. The skills demanded in 2025 prioritize production readiness over research novelty.
Organizations and practitioners who master this trifecta will be positioned to build reliable, scalable AI systems that deliver business value. The experimental phase is over. The production phase has begun.
The explosive growth in specialized skills—Multi-Agent Systems (+245%), Foundation Model Adaptation (+267%), Responsible AI (+256%), and LLM Security (+298%)—signals a shift toward sophisticated, production-grade AI systems. The window of opportunity for early adopters remains open, but closing rapidly as these skills transition from emerging to essential.
The imperative is clear: learn, build, deploy, and iterate.
Start with a simple RAG chatbot using LangChain and ChromaDB. Master LCEL and LangGraph for more complex workflows. Implement MLflow tracking for your experiments. Deploy to Kubernetes when you’re ready for production scale. Measure everything, iterate constantly, and ship working systems.
The future of AI belongs to practitioners who can bridge the gap between experimental possibility and production reality. That gap is your opportunity.
Key Resources to Get Started
Official Documentation:
- LangChain Documentation - Complete framework reference and tutorials
- LangGraph Repository - Stateful agent workflows
- OpenAI Prompt Engineering Guide - Prompt best practices
- Azure MLOps Best Practices - Production MLOps patterns
GitHub Repositories:
- RAG Techniques - Production-ready RAG implementations
- RAGFlow - Leading open-source RAG engine
- Simple Local RAG - Complete local implementation
Learning Platforms:
- LangChain Academy - Official courses
- DataCamp LangGraph Tutorial - Hands-on agent development
Blogs and Publications:
- Pinecone Learning Hub - Vector databases and RAG
- LangChain Blog - Latest framework updates
Share :
Stay Ahead in Tech
Join thousands of developers and tech enthusiasts. Get our top stories delivered safely to your inbox every week.
No spam. Unsubscribe at any time.








