Agents Training Agents: A practical architecture for autonomous self-improvement
- Türker Şentürk
- AI
- 05 Dec, 2025
- 6 min read
What if an AI agent could look at a piece of content and think, “Huh, I don’t know much about this”—and then do something about it?
Not just flag it for a human. Actually go out, find relevant data, validate it, verify it, and eventually use it to improve itself.
This isn’t science fiction. It’s a practical architecture I’ve been thinking about, and I want to walk you through it.
The Core Idea
Traditional fine-tuning is a manual process. You curate a dataset, format it properly, run the training job, evaluate the results. Rinse and repeat.
But what if we could automate the entire loop?
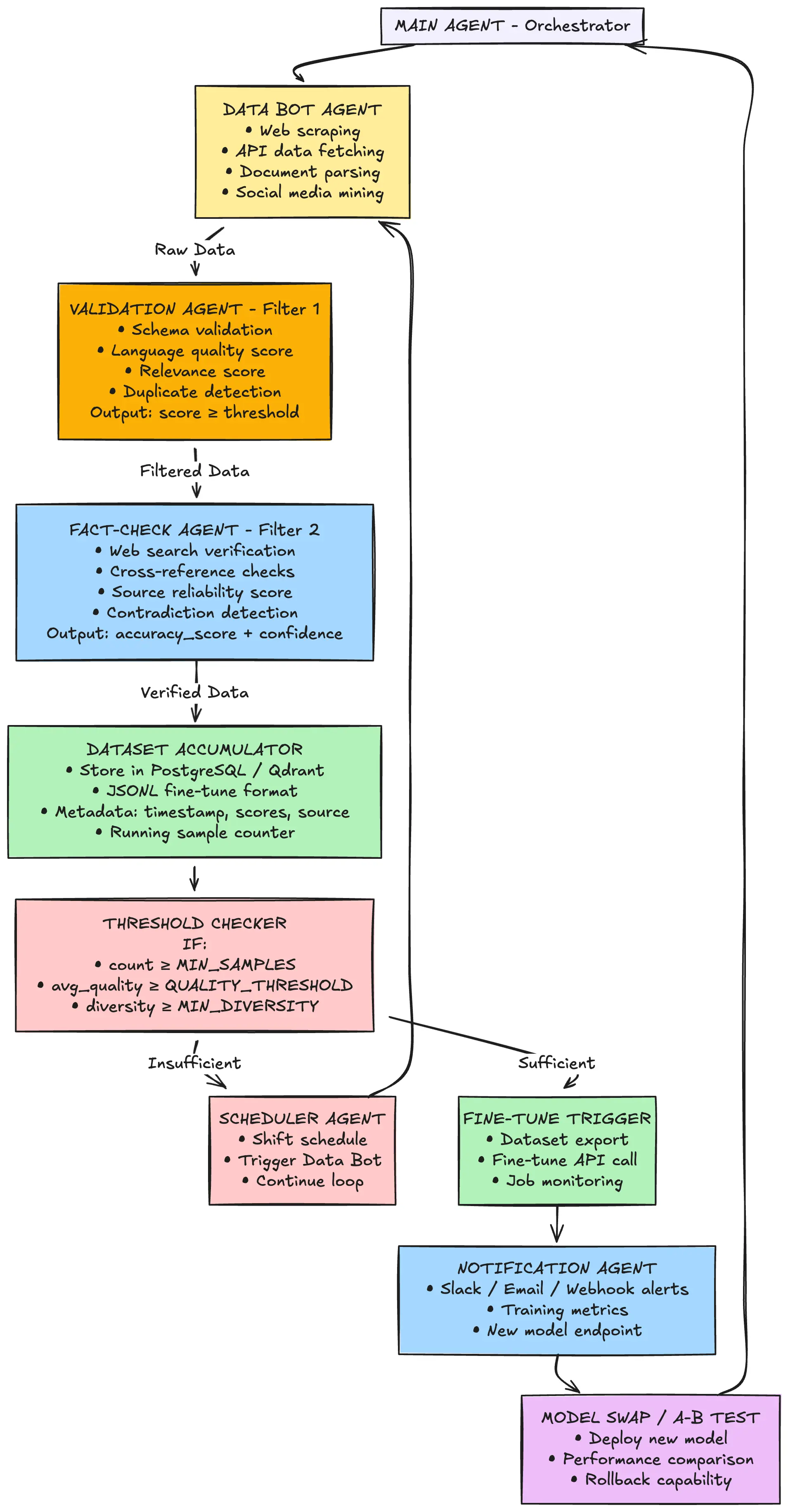
Here’s the basic flow:
- Main Agent realizes it doesn’t know something
- Data Bot goes out and finds relevant information
- Validation Agent filters out garbage
- Fact-Check Agent verifies accuracy
- Dataset Accumulator collects verified data until threshold is met
- Fine-Tune Job runs automatically
- Main Agent gets updated
Simple in concept. Tricky in execution. Let’s break it down.
The Architecture
Each Agent’s Job
The Main Agent (Orchestrator)
This is your primary model—the one that actually talks to users or performs tasks. Its job in this system is simple: know what it doesn’t know.
When the Main Agent encounters a topic it’s uncertain about, it logs that uncertainty. More on how it knows in a bit.
Data Bot Agent
The Data Bot is your information gatherer. It doesn’t think; it fetches.
- Monitors RSS feeds for new content
- Scrapes relevant websites
- Pulls from APIs (news, research papers, domain-specific sources)
- Parses documents that get uploaded
The key here is breadth over precision. You want to cast a wide net because the filtering comes later.
Validation Agent
First line of defense against garbage data.
This agent checks:
- Format: Is this actually usable? Can it be converted to training format?
- Language quality: Is this coherent? Well-written? Or is it SEO spam?
- Relevance: Does this match what the Main Agent actually needs?
- Uniqueness: Have we seen this before?
Each piece of data gets a score. Below threshold? Discarded. Above? Moves on.
Fact-Check Agent
This is where it gets interesting.
The Fact-Check Agent doesn’t just look at the data in isolation—it actively verifies claims:
- Runs web searches to cross-reference facts
- Checks against known reliable sources
- Flags contradictions with existing knowledge
- Assigns a confidence score
This is expensive (more API calls, more compute) but crucial. You don’t want to fine-tune your model on misinformation.
Dataset Accumulator
A glorified database with some logic:
- Stores verified data in fine-tune-ready format (JSONL)
- Tracks running statistics: count, average quality, topic diversity
- Knows when you’ve hit the magic number
The threshold isn’t just “do we have enough samples?” It’s:
- Quantity: Minimum sample count (say, 1000)
- Quality: Average quality score above threshold
- Diversity: Not all the same topic/style
The Fine-Tune Trigger
When all conditions are met:
- Export the dataset
- Call fine-tuning API (OpenAI, Replicate, or your local setup)
- Monitor the job
- Run evaluation benchmarks on the new model
- If it passes: deploy and notify
- If it fails: analyze and adjust
The Critical Question: How Does the Agent Know What It Doesn’t Know?
This is where most “self-improving AI” concepts fall apart. Here are three practical approaches:
Approach 1: Embedding Distance
topic_embedding = embed(new_topic)
knowledge_centroid = get_centroid(existing_knowledge_base)
distance = cosine_distance(topic_embedding, knowledge_centroid)
confidence = 1 - normalize(distance)If the topic is far from what the model “knows” (represented by its fine-tuning data or RAG corpus), confidence is low.
Approach 2: Self-Interrogation
Ask the model about the topic:
- Vague, generic answers → low confidence
- Specific, verifiable claims → high confidence
- “I don’t know” → confidence = 0
Simple but surprisingly effective.
Approach 3: RAG Similarity Check
Search your vector database for relevant chunks:
- Many high-similarity results → “I know this”
- Few or no results → “This is new territory”
Dealing with Thresholds
Here’s a subtle but important point: not all topics deserve equal curiosity.
Your agent probably shouldn’t care equally about everything. A real estate AI doesn’t need to know about sports scores. A coding assistant doesn’t need deep knowledge of celebrity gossip.
So you need a topic-specific threshold:
curiosity_thresholds:
core_domain:
real_estate: 0.2 # Very curious
property_law: 0.3 # Curious
market_trends: 0.25 # Curious
adjacent:
finance: 0.5 # Somewhat curious
construction: 0.4 # Moderately curious
irrelevant:
sports: 0.99 # Don't care
entertainment: 0.95 # Don't careWhen the “stress” (uncertainty × interest) exceeds the threshold, the research loop triggers.
The Feedback Loop Problem
Here’s what most architectures miss: how do you know the fine-tuning actually helped?
You need an evaluation step:
- Run benchmark suite BEFORE fine-tuning
- Run SAME benchmark AFTER fine-tuning
- Compare:
- Performance improved → Deploy
- Performance same → Maybe not worth it
- Performance degraded → Reject and investigate
Without this, you’re not building a self-improving system. You’re building a self-modifying system. That’s dangerous.
Implementation Notes
If you’re thinking about building this, here’s my practical advice:
Start small. Don’t try to build the whole loop at once. Start with just Data Bot → Validation → Storage. Get that working reliably first.
Async everywhere. Fact-checking is slow. Fine-tuning is slow. Design for asynchronous workflows from day one.
Log everything. You’ll need to debug why a certain piece of data made it through (or didn’t). Comprehensive logging is not optional.
Human-in-the-loop escape hatch. Even if the goal is autonomy, you want the ability to pause, inspect, and override. At least in v1.
Consider cost. Every agent call costs money. Every fine-tune job costs money. Build in cost tracking and circuit breakers.
What This Isn’t
Let me be clear about what this architecture is NOT:
- AGI: This is domain-specific improvement, not general intelligence
- Unsupervised: You still define the interest areas and thresholds
- Guaranteed to work: Fine-tuning can fail, data can be bad, evaluation can be flawed
- A replacement for human oversight: It’s an automation tool, not an autonomous entity
Think of it as automated domain adaptation—a system that can get better at specific things without you manually curating every dataset.
Wrapping Up
The pieces for this kind of system already exist:
- Multi-agent frameworks (LangGraph, CrewAI, n8n with AI nodes)
- Fine-tuning APIs (OpenAI, Together, Replicate)
- Vector databases for knowledge tracking (Qdrant, Pinecone)
- Evaluation frameworks (various benchmarks, custom test suites)
The challenge is orchestrating them into a coherent loop with proper safeguards.
Is it worth building? Depends on your use case. If you have a domain where knowledge evolves quickly and you’re constantly re-training models manually, this could be a game-changer.
If you’re just building a chatbot… probably overkill.
In the next post, I’ll dig into something that came up while designing this: the “Curiosity Engine” and why we shouldn’t copy how human brains handle learning—because human brains have some serious bugs.
Share :
Stay Ahead in Tech
Join thousands of developers and tech enthusiasts. Get our top stories delivered safely to your inbox every week.
No spam. Unsubscribe at any time.








